
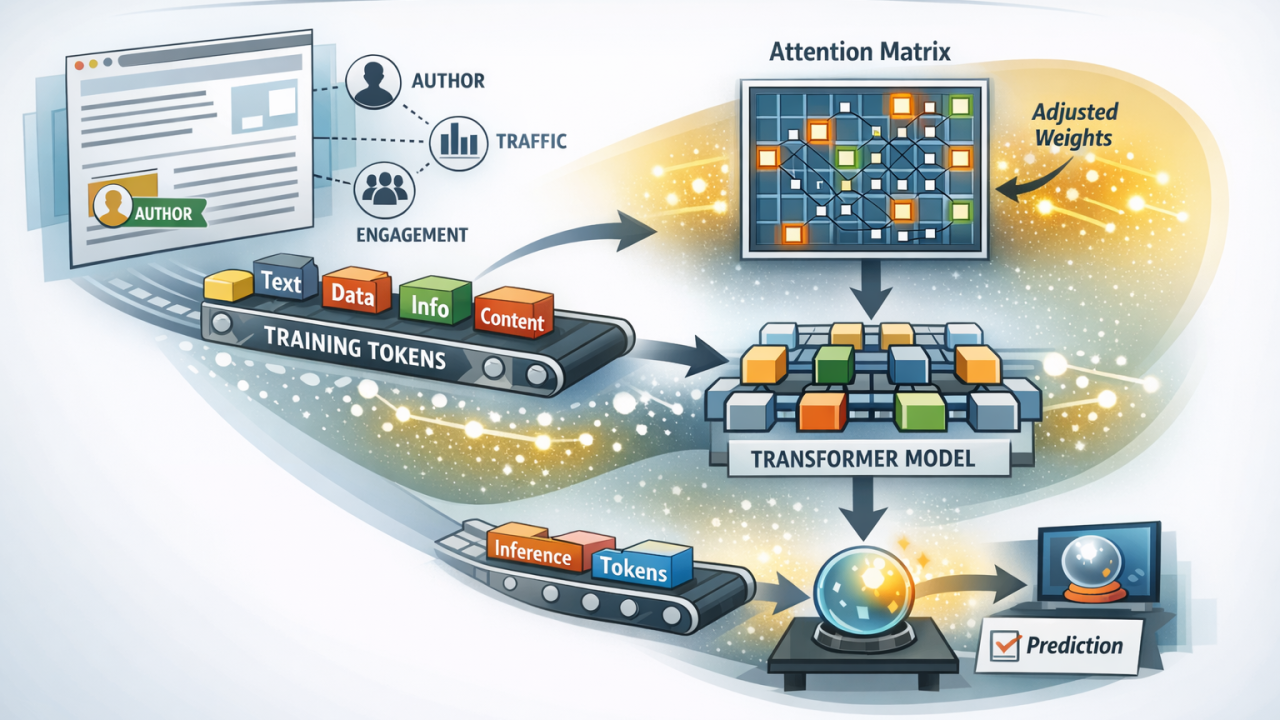
Patent Google US20250103662 opisuje, jak sygnały na poziomie dokumentu - autorytet linków, świeżość, ruch i zaangażowanie - są wbudowane bezpośrednio w macierze uwagi transformerów, czyniąc wiarygodność źródła strukturalną częścią tego, jak modele rozumieją jego treść.
Czego dotyczy patent?
Patent opisuje system łączący modele oparte na transformerach z sygnałami rankingowymi na poziomie dokumentu, takimi jak autorytet oparty na linkach, świeżość, ruch i zaangażowanie.
Podstawowy problem, który adresuje, jest fundamentalny:
Transformery doskonale rozumieją relacje między tokenami, ale tradycyjnie ignorują znaczenie dokumentu, który te tokeny zawiera. W kontekście stron internetowych oznacza to, że konwencjonalne mechanizmy uwagi skupiają się na tym, co jest napisane, a nie skąd pochodzi.
Wynalazek wprowadza sposób na włączenie sygnałów strony internetowej - sygnałów dotyczących całego dokumentu - i wykorzystanie ich do korygowania macierzy uwagi modelu transformerowego.
Kluczowe aspekty patentu obejmują:
- tokenizację strony internetowej na sekwencję tokenów treningowych
- powiązanie strony z sygnałami na poziomie dokumentu (autor, ranking, ruch, świeżość, interakcje)
- obliczenie standardowej macierzy uwagi
- korygowanie wag uwagi na podstawie sygnałów dokumentu i progu trafności
- generowanie predykcji przy użyciu skorygowanej uwagi
Jak opisano w Podsumowaniu, system explicite koryguje macierz uwagi przy użyciu sygnałów strony internetowej, zamiast opierać się wyłącznie na informacjach na poziomie tokenów.
Dane patentowe
- Patent / Publikacja: US20250103662 (Zgłoszenie)
- Data zgłoszenia: 21 września 2023
- Data publikacji: 27 marca 2025
- Zgłaszający: Google LLC (Mountain View, CA)
- Wynalazca: Antonino Gulli (Paradiso)
- Oficjalny tytuł: „Unifying Transformers with Link Based Ranking"
Kluczowe elementy patentu
1. Sygnały dokumentu / strony internetowej
Patent wprowadza sygnały na poziomie dokumentu opisujące znaczenie całej strony internetowej, a nie poszczególnych tokenów.
Przykłady wymienione explicite w patencie:
Autor
Ranking oparty na linkach
Statystyki ruchu
Data utworzenia
Data modyfikacji
Metryki interakcji
Sygnały te reprezentują informacje kontekstowe o źródle treści.
2. Sekwencja tokenów treningowych
Każdy dokument (np. strona internetowa) jest tokenizowany na sekwencję tokenów treningowych.
Dla stron internetowych:
- tokeny reprezentują słowa lub pod-słowa
- embeddingi są generowane w standardowy sposób
Patent uogólnia to podejście również na inne modalności (obrazy, audio, wideo), jednak przypadek stron internetowych jest najbardziej istotny dla wyszukiwania i SEO.
3. Konstrukcja macierzy uwagi
Model buduje standardowy mechanizm uwagi transformera:
- macierz zapytań (query)
- macierz kluczy (key)
- macierz wartości (value)
- wagi uwagi obliczane przez iloczyny skalarne
Na tym etapie system zachowuje się jak konwencjonalny transformer.
4. Korygowanie macierzy uwagi za pomocą sygnałów dokumentu
To jest kluczowa innowacja.
Po obliczeniu macierzy uwagi system koryguje jej wagi przy użyciu sygnałów na poziomie dokumentu.
Patent opisuje próg trafności:
- jeśli dokument spełnia próg → wagi uwagi są zwiększane
- jeśli go nie spełnia → wagi uwagi są redukowane lub niezmieniane
Znaczenie dokumentu wpływa zatem na to, jak silnie jego tokeny przyczyniają się do rozumienia modelu.
5. Trening a wnioskowanie
Patent wskazuje, że korygowanie uwagi może następować podczas treningu, co następnie wpływa na zachowanie modelu podczas wnioskowania.
Deklarowane korzyści to:
- redukcja halucynacji - model jest ukierunkowany na tokeny z dokumentów o wyższym autorytecie
- lepsze zakotwiczenie - wyniki są oparte na rzeczywistych, zweryfikowanych sygnałami źródłach
Sygnały dokumentu są tu explicite pozycjonowane jako mechanizm zaufania i wiarygodności, a nie tylko dane wejściowe do rankingu.
Implikacje dla SEO
Rozumienie, nie tylko ranking
Sygnały rankingowe mogą kształtować sposób interpretowania treści, a nie tylko jej pozycję. Pytanie przesuwa się od „czy ta strona rankuje?" do „czy ta strona jest traktowana przez model jako wiarygodna?"
Autorytet jako mnożnik wag
Dwie strony mogą zawierać identyczne informacje, ale model może ważyć tokeny jednej z nich mocniej. Autorytet nie tylko podnosi pozycję - może wzmacniać wpływ każdego słowa na stronie.
Świeżość zyskuje znaczenie strukturalne
Daty utworzenia i modyfikacji są explicite sygnałami w tym systemie. Znaczące aktualizacje powiązane z trafnością mogą bezpośrednio wpływać na ważenie uwagi - nie tylko dawać chwilowy boost świeżości.
Zaangażowanie jako sygnał pewności
Ruch i metryki interakcji zasilają zbiór sygnałów dokumentu. Treść, z której użytkownicy faktycznie korzystają, staje się bardziej zaufanym wejściem do modelu - wzorce użytkowania wzmacniają pewność modelu co do źródła.
Strategiczne rekomendacje SEO
Co robić
- Buduj autorytet tematyczny, nie izolowane strony - sygnały na poziomie dokumentu kumulują się w historii treści domeny, nie w pojedynczym artykule
- Wzmacniaj zaufanie na poziomie dokumentu - traktuj treść jako coś, czemu modele powinny ufać, a nie tylko indeksować
- Udostępniaj autorstwo explicite - patent wymienia autorstwo jako nazwany sygnał; upewnij się, że treść wyraźnie wskazuje eksperta, który ją stworzył
- Aktualizuj treść sensownie - data modyfikacji jest sygnałem; zmiany odzwierciedlające rzeczywistą aktualizację informacji mają większe znaczenie niż kosmetyczne edycje
- Zdobywaj linki sygnalizujące autorytet Google'owi - ranking oparty na linkach to fundamentalny sygnał w tym patencie; linki z wiarygodnych źródeł bezpośrednio zasilają mechanizm korygowania uwagi
Czego unikać
- Założenia, że „świetna treść wystarczy" - patent pokazuje, że dwa identyczne teksty mogą być ważone inaczej w zależności od sygnałów ich źródła
- Publikowania treści oderwanych od kontekstu domeny - skupienie tematyczne konsoliduje sygnały na poziomie dokumentu; rozproszone tematy je rozmywają
- Masowych aktualizacji bez rzeczywistej zmiany informacyjnej - aktualizowanie dat modyfikacji przez powierzchowne edycje może nie spełniać progu trafności
Praktyczne przykłady wdrożenia na podstawie patentu
Huby treści z ważeniem autorytetu
Twórz struktury hub-and-spoke z jednym głównym dokumentem referencyjnym. Konsolidacja sygnałów na poziomie dokumentu w ten sposób klaruje znaczenie i zwiększa prawdopodobieństwo wzmocnienia uwagi.
Strategia aktualizacji zgodna z progami trafności
Aktualizuj treść, gdy zmienia się intencja lub dane - nie kosmetycznie. Data modyfikacji staje się znaczącym sygnałem, a nie szumem, gdy zmiana odzwierciedla rzeczywistą wartość informacyjną.
Linkowanie wewnętrzne jako konsolidacja sygnałów
Używaj linków wewnętrznych do wzmacniania, które dokumenty mają największy autorytet. Linkowanie wewnętrzne wzmacnia sygnały rankingowe, które mogą bezpośrednio wpływać na mechanizm ważenia uwagi.
Jasność autorstwa i źródła
Wyraźnie określaj, kto stworzył treść i dlaczego jest do tego kompetentny. Autorstwo jest explicite wymienione jako sygnał dokumentu - to nie miękki sygnał E-E-A-T, to twarde wejście do systemu.
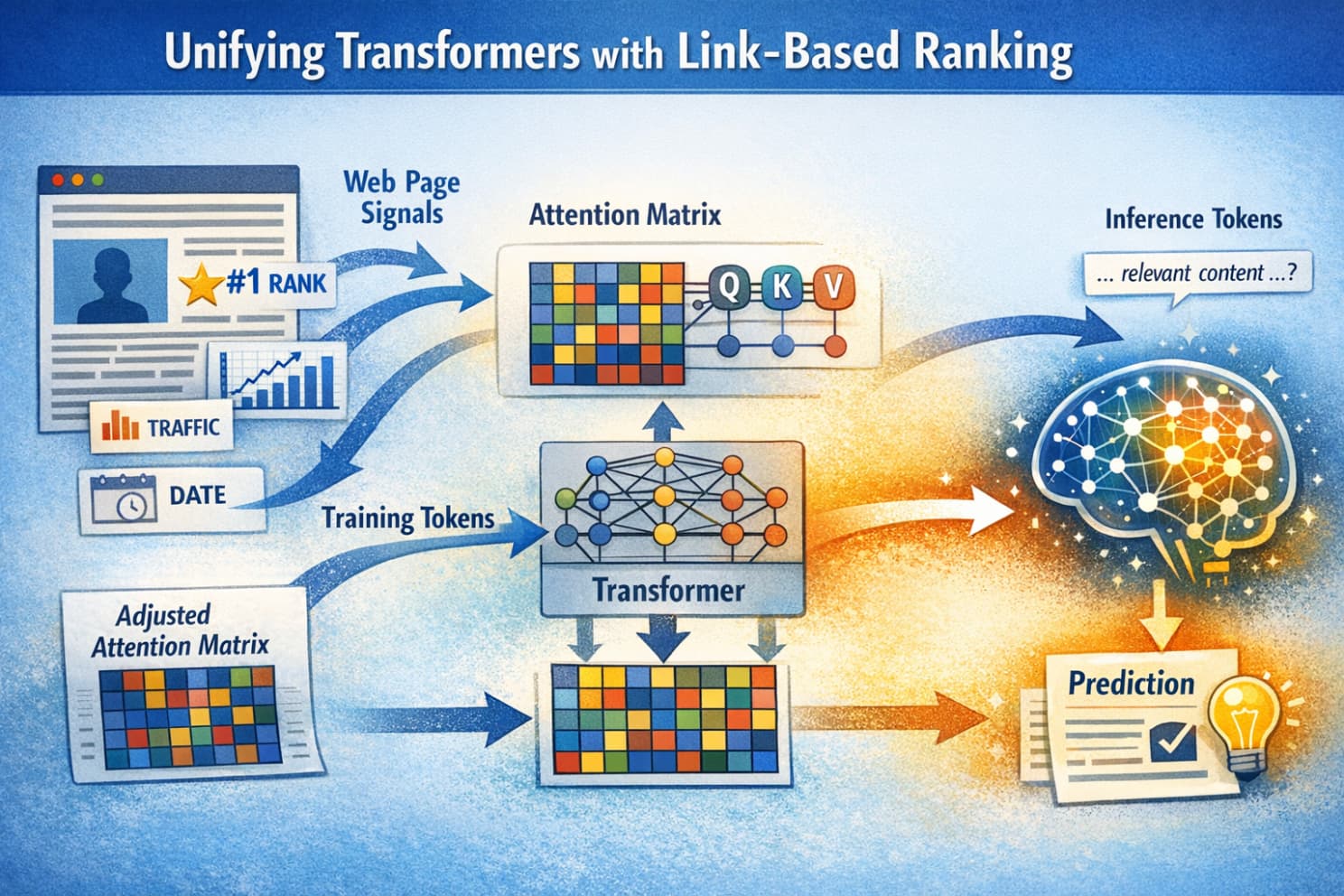
Podsumowanie
Ten patent to silny sygnał kierunkowy.
Pokazuje, jak sygnały rankingowe na poziomie dokumentu - w tym autorytet oparty na linkach, świeżość, zaangażowanie i zaufanie - mogą być zintegrowane bezpośrednio z mechanizmami uwagi transformerów.
Nie w sensie „sygnały rankingowe decydują, kto jest na #1" - ale w głębszy, bardziej strukturalny sposób:
Sygnały rankingowe mogą wpływać na to, czemu model poświęca uwagę i jak bardzo ufa tokenom, które przetwarza.
Szczególnie ważne jest to, jak sam wynalazca formułuje cel patentu.
Według Antonino Gulliego praca ta explicite dotyczy łączenia LLM z wyszukiwaniem - wykorzystania rzeczywistych stron internetowych i ich sygnałów do zakotwiczenia dużych modeli językowych. Motywacja jest jasna: choć LLM są płynne, mogą halucynować. Wyszukiwanie natomiast dostarcza zweryfikowanych, kontekstowych i bogatych w sygnały danych.
Wstrzykując sygnały na poziomie dokumentu do uwagi:
- halucynacje mogą być redukowane przez ukierunkowanie uwagi na wiarygodne źródła
- jakość i dokładność poprawiają się, ponieważ model skupia się na zaufanych, aktualnych i autorytatywnych dokumentach
- wyjaśnialność rośnie, bo wyniki można powiązać z kontekstem i sygnałami na poziomie dokumentu
Innymi słowy, ten patent nie dotyczy tylko rankingu. Dotyczy uwagi uwzględniającej zaufanie.
W erze, gdy wyszukiwanie jest coraz bardziej mediowane przez modele - podsumowania AI, asystenci i odpowiedzi generatywne - przewaga konkurencyjna przesuwa się ku wydawcom, którzy łączą:
- mocną treść (trafność i klarowność na poziomie tokenów) z
- mocnymi sygnałami (autorytet, świeżość, zaangażowanie i zaufanie na poziomie dokumentu)
Patenty to nie ogłoszenia produktów. Ale ten wygląda jak czytelny schemat tego, jak klasyczne sygnały SEO i rozumienie w stylu LLM zbiegają się w jeden mechanizm.
Jeśli uwaga to kierownica nowoczesnych modeli, to sygnały na poziomie dokumentu mogą być wspomaganiem kierownicy.
I SEO, w tym świecie, nie polega już na optymalizowaniu stron - polega na projektowaniu dokumentów, na których modele mogą bezpiecznie polegać.
Kluczowe wnioski
Patent US20250103662 wprowadza metodę korygowania macierzy uwagi transformerów za pomocą sygnałów rankingowych na poziomie dokumentu, czyniąc autorytet, świeżość, autorstwo i zaangażowanie strukturalnymi wejściami do przetwarzania treści przez modele - a nie tylko czynnikami rankingowymi.
Kluczowa innowacja tkwi w mechanizmie progu trafności: dokumenty spełniające próg mają wagi uwagi ich tokenów wzmacniane, podczas gdy słabsze dokumenty są depriorytetyzowane. Tworzy to bezpośredni kanał, przez który klasyczne sygnały SEO wpływają na zachowanie transformerów.
Dla strategów SEO implikacja jest jasna: sukces zależy od budowania dokumentów, którym modele mogą ufać - łączących autorytet tematyczny, explicite autorstwo, sensowną świeżość i trafność popartą zaangażowaniem. Gra rankingowa i gra o uwagę to teraz ta sama gra.