
Patent Google US10268680B2, opracowany przez Piotra Tąkiela – polskiego starszego inżyniera oprogramowania w Google – wprowadza zaawansowany system zarządzania dialogiem człowiek-komputer. Jego główna innowacja to "kontekstowa struktura danych" – dynamiczna struktura pamięci utrzymująca i zarządzająca tematami rozmów, rozumiejąca ich relacje semantyczne i śledząca ich bieżącą trafność. Odczytanie tego patentu przez pryzmat SEO ujawnia uderzające podobieństwa do sposobu, w jaki Google może oceniać autorytet tematyczny w wyszukiwaniu.
Informacje ogólne
Metadane patentu
- Numer patentu: US10268680B2
- Data udzielenia: 23 kwietnia 2019
- Wynalazca: Piotr Tąkiel (polski starszy inżynier oprogramowania w Google)
- Zgłaszający: Google LLC, Mountain View, CA
- Oficjalny tytuł: "Context-aware human-to-computer dialog"
- Główna innowacja: Kontekstowa struktura danych jako dynamiczna struktura pamięci do zarządzania tematami rozmów
Przegląd patentu i główna innowacja
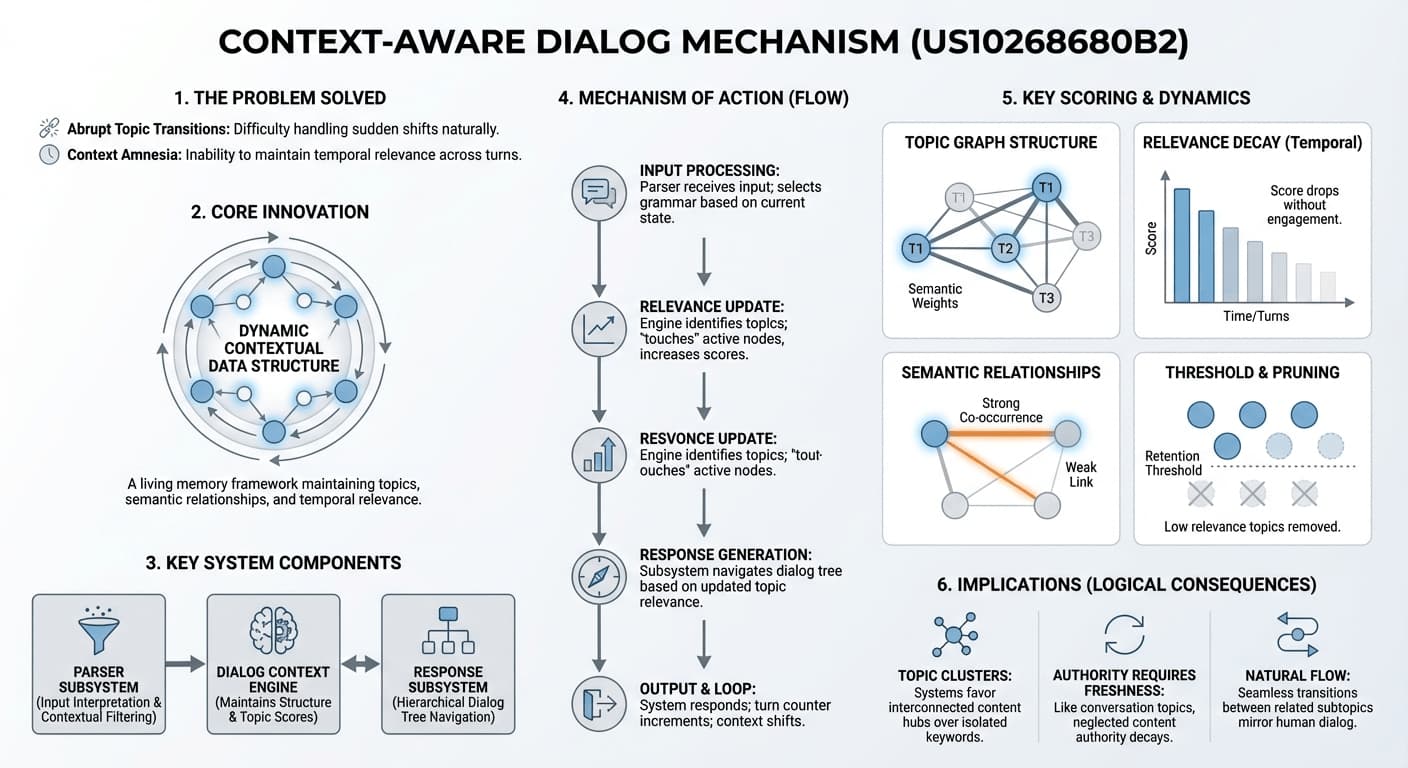
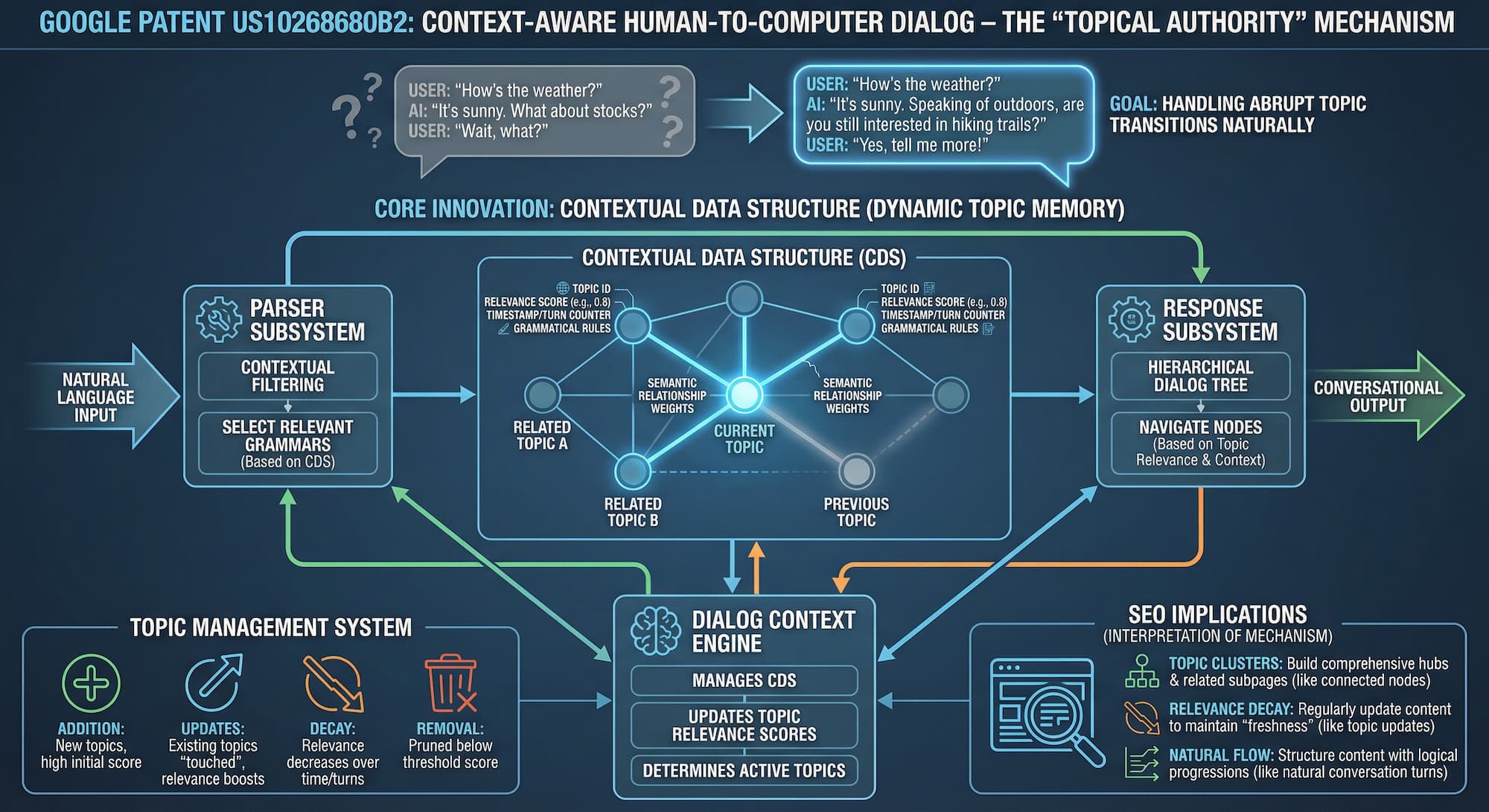
Patent rozwiązuje jedno z fundamentalnych wyzwań konwersacyjnej AI: naturalne i efektywne obsługiwanie nagłych zmian tematów. Gdy użytkownik nagle przeskakuje z jednego tematu na inny – a potem wraca – naiwny system traci kontekst, powtarza się lub zadaje zbędne pytania wyjaśniające.
Rozwiązaniem systemu jest "kontekstowa struktura danych" – struktura pamięci zaimplementowana jako graf nieskierowany. Graf ten na bieżąco śledzi, które tematy są aktywne w rozmowie, jak silnie powiązane są ze sobą te tematy i jak niedawno każdy z nich był przywołany. Tematy, które nie są wspominane, stopniowo tracą trafność; tematy, które są wielokrotnie przywołowane razem, wzmacniają swoje połączenia semantyczne.
Kluczowy wniosek z patentu: trafność nie jest binarna (trafne/nietrafne), lecz oceniana, wrażliwa na czas i zależna od relacji. Temat nie staje się natychmiast nieistotny, gdy rozmowa się przesuwa – zanika i może zostać ożywiony. To właśnie mechanizm, którego system używa do rozumienia "o czym rozmawialiśmy".
Architektura techniczna i działanie
System działa poprzez kilka wzajemnie powiązanych komponentów, które współpracują w przetwarzaniu, rozumieniu i odpowiadaniu na dane wejściowe w języku naturalnym:
Podsystem parsera
Stanowi pierwszą warstwę przetwarzania – interpretuje dane wejściowe w języku naturalnym. Stosuje filtrowanie kontekstowe do wyboru odpowiednich gramatyk z większej bazy reguł – dynamicznie, na podstawie bieżącego stanu rozmowy. Reguły gramatyczne zależą od tego, które tematy są aktualnie aktywne.
Podsystem odpowiedzi
Zarządza przepływem rozmowy poprzez hierarchiczne drzewo dialogu. Każdy węzeł reprezentuje określony proces konwersacyjny; relacje rodzic-dziecko odzwierciedlają naturalną progresję dialogu. System nawiguje między węzłami na podstawie trafności tematów i bieżącego kontekstu rozmowy.
Silnik kontekstu dialogu
Serce systemu. Utrzymuje kontekstową strukturę danych, zarządza wynikami trafności tematów i na bieżąco aktualizuje stan rozmowy. Określa, które tematy są aktualnie aktywne i trafne – to "pamięć robocza" całego systemu dialogowego.
Kluczowe komponenty techniczne
1. Kontekstowa struktura danych
Struktura jest zaimplementowana jako graf nieskierowany. To nie jest prosta lista – to sieć relacyjna, w której tematy są połączone podobieństwem semantycznym, a każdy węzeł niesie bogate metadane o swoim bieżącym stanie w rozmowie.
Każdy węzeł grafu zawiera:
- Identyfikator tematu – czym jest dany temat
- Wynik trafności – jak aktualnie aktywny i ważny jest ten temat
- Znacznik czasu lub licznik tur rozmowy – kiedy temat był ostatnio przywołany
- Powiązane reguły gramatyczne – które reguły parsowania mają zastosowanie w tym kontekście tematycznym
- Wagi relacji semantycznych – jak silnie ten temat łączy się z innymi w grafie
Krawędzie między węzłami reprezentują relacje semantyczne. Dwa tematy, które często współwystępują w rozmowie, z czasem rozwijają silniejsze wagi krawędzi.
2. Mechanizm punktacji trafności
System stosuje wieloczynnikowy algorytm oceny. Wynik trafności tematu nie jest statyczny – jest przeliczany na bieżąco na podstawie kilku czynników:
Bliskość czasowa
Jak niedawno temat był omawiany. Temat wspomniany dwie tury temu ma wyższy wynik niż wspomniany dwadzieścia tur temu.
Liczba tur rozmowy
Liczba wymian od ostatniego przywołania tematu. Więcej minionych tur = niższy wynik trafności.
Siła relacji semantycznych
Wagi powiązań z aktualnie aktywnymi tematami. Powiązany temat może utrzymać wyższą trafność nawet bez bezpośredniego wspomnienia.
Dwa kolejne czynniki uzupełniają formułę punktacji: trwałość tematu (jak długo dany typ tematu naturalnie pozostaje trafny w rozmowach tego rodzaju) oraz wartości progowe (minimalne wyniki, poniżej których tematy są całkowicie usuwane z aktywnego rozważania).
3. Dobór i zastosowanie gramatyki
System implementuje dwuetapowe podejście do przetwarzania gramatyki, łączące trafność tematyczną bezpośrednio z parsowaniem języka:
Etap 1: Filtrowanie kontekstowe
- Ocena bieżącego kontekstu rozmowy
- Identyfikacja trafnych tematów z kontekstowej struktury danych
- Wybór odpowiednich reguł gramatycznych na podstawie wyników trafności
Etap 2: Zastosowanie gramatyki
- Zastosowanie wybranych gramatyk do parsowania danych wejściowych
- Generowanie wielu możliwych interpretacji
- Ranking interpretacji na podstawie trafności kontekstowej
4. System zarządzania tematami
Tematy nie są po prostu "aktywne" lub "nieaktywne". System zarządza ciągłym cyklem życia każdego tematu w rozmowie:
- Dodanie: Nowe tematy są dodawane z wysoką początkową oceną trafności przy pierwszym wprowadzeniu.
- Odświeżenia ("aktualizacje"): Istniejące tematy są aktualizowane przy przywołaniu – co resetuje lub zwiększa ich wyniki trafności.
- Zanik: Trafność tematu naturalnie maleje z upływem czasu i tur rozmowy, bez żadnego jawnego działania.
- Usuwanie: Tematy, których wynik spada poniżej progu, są całkowicie usuwane z aktywnej struktury.
5. Przetwarzanie relacji semantycznych
System identyfikuje powiązania między tematami poprzez kontekst rozmowy, wzmacnia relacje między często współwystępującymi tematami, dostosowuje wagi relacji na podstawie wzorców konwersacyjnych i używa tych relacji semantycznych do wpływania na wyniki trafności tematów. Temat nieprzywołany przez dziesięć tur może nadal być uznawany za trafny – jeśli aktywnie omawiasz ściśle powiązany z nim temat.
Samo drzewo dialogu jest utrzymywane poprzez obsługę węzła głównego dla nowych wątków rozmowy, tworzenie węzłów potomnych dla specyficznych kontekstów, dynamiczne aktualizacje relacji między węzłami na podstawie zmian tematycznych i zachowanie historii rozmowy dla utrzymania kontekstu. Komponenty te tworzą razem solidny system zdolny do prowadzenia spójnych rozmów nawet przy nagłych zmianach tematów.
Implikacje SEO technologii patentu
Ważna uwaga dotycząca tych rekomendacji SEO
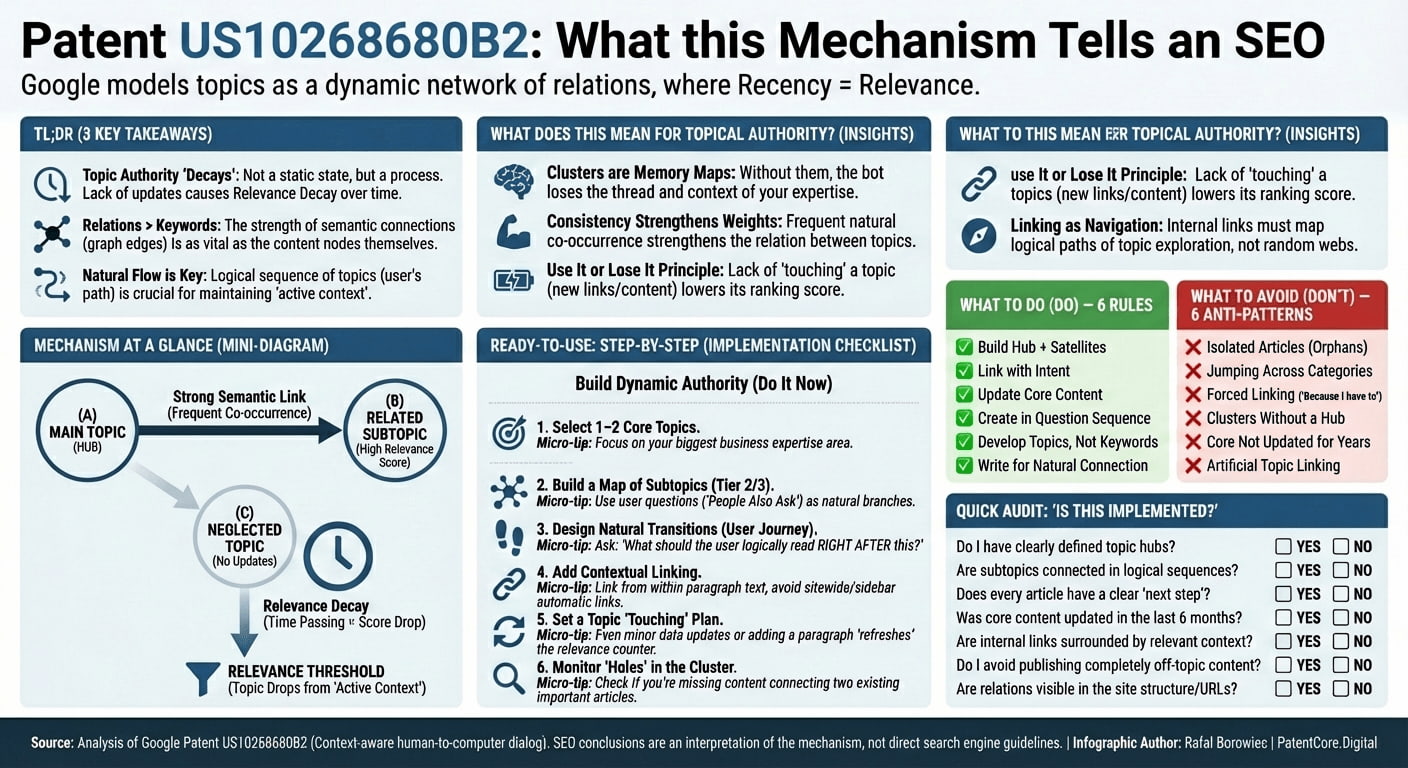
Patent US10268680B2 opisuje konkretnie system zarządzania tematami w rozmowach człowiek-komputer. Nie odnosi się bezpośrednio do treści stron internetowych ani praktyk SEO. Rozumiejąc jednak, jak Google podchodzi do relacji między tematami i trafności w rozmowach, możemy wyciągnąć przemyślane wnioski o tym, jak podobne zasady mogą dotyczyć treści na stronach i SEO.
Poniższe rekomendacje to interpretacje oparte na koncepcjach z patentu – nie bezpośrednie wskazówki od Google. Reprezentują moją analizę tego, jak podejście Google do zarządzania tematami konwersacyjnymi może przekładać się na organizację treści i wyszukiwanie.
Rozumienie relacji między treściami
Patent ujawnia, jak Google może rozumieć relacje między tematami treści – podobnie do tego, jak zarządza tematami rozmów. Ma to kilka ważnych implikacji dla tego, jak strony w ramach witryny są rozumiane w relacji do siebie nawzajem.
Przykład: Jeśli prowadzisz stronę o aparatach fotograficznych, Google może teraz lepiej rozumieć, kiedy naturalnie przechodzisz między powiązanymi tematami, takimi jak "aparaty DSLR" – "obiektywy aparatu" – "filtry do obiektywów", nawet gdy te tematy pojawiają się na różnych podstronach. Kontekstowa struktura danych opisana w patencie sugeruje, że Google może utrzymywać te relacje tematyczne i ich trafność w czasie.
Autorytet tematyczny i zanik trafności
Mechanizm punktacji trafności z patentu dostarcza wskazówek dotyczących tego, jak Google może oceniać autorytet tematyczny. Mechanizm zanikania jest szczególnie znamienny: temat, który nie otrzymuje nowych odświeżeń (odwołań, aktualizacji, powiązanych treści), stopniowo traci swój wynik trafności w rozmowie. Zastosuj to do strony internetowej, a analogia staje się czytelna.
Przykład praktyczny: Jeśli publikujesz kompleksowe treści o "fotografii cyfrowej", ale potem przez dłuższy czas nie aktualizujesz ani nie rozszerzasz tego tematu, skupiając się na innych obszarach – twój autorytet tematyczny może "zanikać", podobnie jak patent obsługuje trafność tematów w rozmowach. Podkreśla to wagę konsekwentnego utrzymywania i aktualizowania treści w ramach podstawowych obszarów tematycznych.
Naturalny przepływ treści
System zarządzania rozmową z patentu sugeruje, że Google ceni naturalne przejścia tematyczne. Zamiast tworzyć izolowane strony ukierunkowane na różne słowa kluczowe, strukturowanie treści jak naturalnej rozmowy – gdzie każda podstrona logicznie prowadzi do następnej – może odzwierciedlać sposób, w jaki patent obsługuje przepływy konwersacyjne.
Zastanów się nad różnicą między stroną z dziesięcioma rozłączonymi podstronami ukierunkowanymi na słowa kluczowe a stroną zorganizowaną wokół jasnej progresji tematycznej: Podstawy fotografii – Typy aparatów – Konkretne recenzje aparatów – Akcesoria – Techniki. Ta druga odzwierciedla sposób działania drzewa dialogu z patentu: każdy węzeł naturalnie łączy się z powiązanymi węzłami, a system nawiguje między nimi na podstawie trafności i siły relacji.
Strategiczne rekomendacje SEO
Buduj klastry tematyczne
Twórz kompleksowe strony-huby dla głównych tematów i rozwijaj powiązane strony podtematyczne, które naturalnie łączą się z hubem. Stosuj linkowanie wewnętrzne wzmacniające relacje tematyczne – odzwierciedlając krawędzie w grafie nieskierowanym z patentu.
Strona-hub
Kompleksowy przewodnik po "Fotografii cyfrowej" – węzeł główny o wysokiej trafności, od którego rozgałęziają się wszystkie powiązane tematy.
Połączone podtematy
Typy aparatów i rekomendacje – Techniki fotografii – Poradniki postprodukcji. Każdy naturalnie wynika z tematu głównego.
Krawędzie semantyczne
Linki wewnętrzne między podtematami, które często współwystępują (np. "obiektywy" – "filtry"), wzmacniają wagi relacji w grafie treści.
Utrzymuj świeżość tematów
Mechanizm zaniku z patentu czyni to imperatywem strategicznym: regularnie aktualizuj podstawowe treści tematyczne, dodawaj nowe powiązane podtematy i utrzymuj aktualne struktury linkowania wewnętrznego. Praktycznym rozwiązaniem jest stworzenie kalendarza treści zapewniającego regularne aktualizacje najważniejszych klastrów tematycznych – zapobiegając "zanikowi tematów" opisanemu w patencie.
Nie chodzi o zmienianie treści dla samej zmiany. Chodzi o sygnalizowanie Google, że temat jest aktywnie utrzymywany i autorytatywny – odpowiednik odświeżenia węzła tematycznego w grafie rozmowy i zaktualizowania jego wyniku trafności.
Twórz naturalne przejścia między tematami
Stosuj logiczne progresje treści, dodawaj kontekstowe linki wewnętrzne i rozwijaj treści antycypujące pytania użytkowników – tak jak spójna rozmowa naturalnie prowadzi od jednego tematu do następnego.
Przykładowa struktura: Artykuł "Aparaty DSLR" – "Zrozumienie obiektywów aparatu" (naturalny następny temat) – "Jak wybrać obiektyw do aparatu DSLR" (logiczna progresja). Każda strona zasługuje na swoje miejsce w sekwencji, będąc naturalną kontynuacją tego, co ją poprzedza.
Czego unikać
Tworzenie izolowanych treści
❌ Nie rób: Twórz samodzielne strony ukierunkowane na słowa kluczowe bez powiązania tematycznego.
✓ Zamiast tego: Zadbaj, by każdy nowy fragment treści logicznie łączył się z istniejącymi klastrami tematycznymi. Przykład błędu: posiadanie strony o fotografii i nagle tworzenie izolowanej strony o "najlepszych ekspresach do kawy" tylko dlatego, że ma dużą liczbę wyszukiwań.
Sztuczne relacje tematyczne
❌ Nie rób: Wymuszaj połączenia między niepowiązanymi tematami.
✓ Zamiast tego: Skup się na budowaniu autentycznej ekspertyzy tematycznej w powiązanych obszarach. Zły przykład: próba powiązania "recenzji aparatów" z "poradami odchudzającymi" tylko dlatego, że oba tematy są popularne.
Zaniedbywanie utrzymania treści
❌ Nie rób: Pozwól, by podstawowe treści tematyczne stały się przestarzałe.
✓ Zamiast tego: Regularnie aktualizuj i rozszerzaj klastry tematyczne. Zły przykład: posiadanie "Ostatecznego przewodnika po aparatach cyfrowych" z 2019 roku, nieaktualizowanego od momentu publikacji – węzeł tematyczny w zaniku.
Przyszłe rozważania strategiczne
Budowanie autorytetu tematycznego
Skup się na budowaniu kompleksowego pokrycia podstawowych tematów. Rozwijaj treści demonstrujące głęboką ekspertyzę. Utrzymuj stałe skupienie tematyczne w czasie – nie jako jednorazowy wysiłek, lecz trwałe zobowiązanie utrzymujące wysokie wyniki trafności.
Planowanie architektury treści
Projektuj strukturę strony wokół naturalnych relacji tematycznych. Planuj rozwój treści wspierający wzrost klastrów tematycznych. Twórz jasne ścieżki tematyczne przez swoją stronę – odzwierciedlając strukturę drzewa dialogu, gdzie każdy węzeł naturalnie prowadzi do swoich potomków.
Mapowanie ścieżki użytkownika
Rozumiej, jak użytkownicy naturalnie przemieszczają się między tematami. Twórz treści wspierające naturalne eksplorowanie tematów. Antycypuj i odpowiadaj na powiązane pytania – tak jak drzewo dialogu z patentu antycypuje i obsługuje naturalne progresje konwersacyjne.
Strategia świeżości treści
Opracuj systemy regularnych aktualizacji treści. Monitoruj trafność tematyczną na całej stronie. Planuj ciągłe rozszerzanie i udoskonalanie tematów – odpowiednik mechanizmu odświeżania z patentu, który resetuje i zwiększa wyniki trafności.
Wnioski dla SEO
Sukces w SEO będzie coraz bardziej zależał od budowania prawdziwej ekspertyzy tematycznej i tworzenia treści, które naturalnie przepływają między powiązanymi tematami – podobnie do tego, jak przebiegają ludzkie rozmowy.
- Klastry tematyczne wygrywają z izolowanymi stronami – powiązane treści odzwierciedlają graf relacji semantycznych z patentu i mogą sygnalizować silniejszy autorytet tematyczny
- Trafność zanika bez utrzymania – regularne aktualizacje treści nie są opcjonalne; to mechanizm utrzymujący wysokie wyniki autorytetu tematycznego
- Naturalne przejścia mają znaczenie – treści powinny płynnie łączyć się między tematami, nie skakać między rozłączonymi obszarami
- Połączenia semantyczne kumulują się – im silniej powiązane są ze sobą twoje strony, tym wyższa domyślna trafność każdej strony w klastrze
- Unikaj utraty kontekstu – podobnie jak system dialogowy penalizuje przerwy kontekstowe, nagłe zmiany tematyczne lub rozłączone treści mogą podważać postrzegany autorytet
Należy skupić się na rozwijaniu kompleksowych, powiązanych struktur treści, które demonstrują jasny autorytet tematyczny i utrzymują trafność w czasie. Nie optymalizacja pod słowa kluczowe – architektura tematyczna.

Dla tych, którzy chcą zrozumieć ten patent jeszcze lepiej
1. Kontekst to dynamiczna, oceniana struktura – nie stan statyczny
Patent wprowadza kontekstową strukturę danych zaimplementowaną jako graf nieskierowany. Kontekst rozmowy nie jest binarny (aktywny/nieaktywny), nie jest liniowy i nie jest natychmiast resetowany przy zmianie tematu. Zamiast tego jest oceniany, wrażliwy na czas, zależny od relacji i przeliczany na bieżąco.
Każdy węzeł tematyczny zawiera:
- Wynik trafności
- Znacznik czasu lub licznik tur
- Wagi relacji semantycznych do innych węzłów
- Powiązane reguły gramatyczne
Podstawowa zasada: trafność zanika stopniowo, nie natychmiast. To jeden z najpotężniejszych sygnałów architektonicznych w patencie.
2. Trafność jest wieloczynnikowa i ciągła
Trafność tematyczna jest matematyczna i kumulatywna, nie heurystycznym zgadywaniem. Zależy jednocześnie od wielu czynników:
- Bliskość czasowa – jak niedawno temat był przywołany
- Liczba tur – ile wymian minęło od ostatniego wspomnienia
- Siła połączeń semantycznych – wagi relacji z aktualnie aktywnymi tematami
- Charakterystyka trwałości tematu – jak długo ten typ tematu naturalnie pozostaje trafny
- Reguły przycinania progowego – minimalne wyniki, poniżej których temat jest usuwany z aktywnego rozważania
Temat może pozostawać trafny nawet jeśli nie jest bezpośrednio wspominany – jeśli jest semantycznie połączony z aktualnie aktywnymi tematami. To jest kluczowe: obecność nie jest wymagana do trafności.
3. Relacje wzmacniają się przez współwystępowanie
Krawędzie między tematami mają wagi. Kiedy tematy często współwystępują, ich waga relacji rośnie – a wraz z nią rośnie ich wzajemna zdolność do odnawiania trafności drugiego. System uczy się wzorców bliskości tematycznej w czasie.
To nie jest tylko przechowywanie. To adaptacyjne modelowanie semantyczne. Graf nie jest migawką – to żywa struktura, która uczy się z rozmowy.
4. Dobór gramatyki jest blokowany kontekstem
Parsowanie nie jest uniwersalne. Reguły gramatyczne są dobierane na podstawie aktywnych tematów, progów trafności i bieżącego stanu grafu kontekstowego. Praktyczna konsekwencja: to samo zdanie może być parsowane różnie w zależności od tego, które tematy są aktualnie aktywne w kontekstowej strukturze danych. Interpretacja danych wejściowych jest bezpośrednio zależna od aktywacji grafu kontekstowego – system czyta język przez pryzmat tego, co aktualnie "wie", że jest trafne.
5. Tematy mają cykl życia
Każdy temat przechodzi przez cztery odrębne etapy: wprowadzenie (wysoki początkowy wynik trafności przy pierwszym wspomnieniu), odświeżenie (aktualizacja wyniku przy kolejnym przywołaniu), zanik (stopniowy spadek trafności w czasie i turach) i przycinanie (usunięcie gdy wynik spada poniżej progu). System jest zaprojektowany tak, by unikać nagłej utraty kontekstu, jednocześnie zapobiegając nieskończonemu gromadzeniu pamięci. To jest kontrolowane zapominanie – nie arbitralne usuwanie, lecz przemyślany mechanizm utrzymujący aktywny kontekst zarówno aktualnym, jak i ograniczonym.
Zestawienie z szerszą wiedzą o innych patentach Google
Zestawiając ten patent z wzorcami widocznymi w innych systemach Google – Navboost, indeksowanie oparte na frazach, systemy oceny jakości, odzyskiwanie oparte na encjach, łańcuchy zapytań, ranking oparty na sesji – ujawnia się spójna filozofia architektoniczna tkwiąca pod nimi wszystkimi.
1. Modelowanie oparte na grafach jest tematem przewodnim. Graf nieskierowany tego patentu silnie koresponduje z systemami indeksowania opartymi na encjach, Knowledge Graph, indeksowaniem opartym na frazach, grafami dokument-temat i systemami punktacji opartymi na linkach. Google konsekwentnie modeluje informacje jako węzły + ważone krawędzie + funkcje punktacji + mechanizmy zaniku. To nie jest odosobnione – to filozofia architektoniczna powtarzająca się we wszystkich systemach.
2. Zanik trafności odzwierciedla patenty o świeżości i łańcuchach zapytań. Mechanizm zaniku jest analogiczny do oceny aktualności zapytań, historycznych modeli kliknięć, kontekstu wyszukiwania opartego na sesji i systemów wzmacniania podobnych do Navboost. We wszystkich patentach Google konsekwentnie wzmacnia często wzmacniane elementy, stopniowo redukuje wagę nieaktywnych elementów i używa progów do przycinania. Ten patent dialogowy doskonale wpisuje się w ten wzorzec.
3. Wzmacnianie przez współwystępowanie odzwierciedla indeksowanie oparte na frazach. Wcześniejsze patenty Google opisują frazy zyskujące na znaczeniu na podstawie częstości współwystępowania, dokumenty połączone wspólnymi frazami i relacje między terminami wpływające na scoring. Ten system dialogowy robi to samo – ale dla tematów rozmów. Zasada jest spójna w różnych kontekstach: wielokrotne skojarzenie wzmacnia wagę relacji.
4. Przycinanie progowe jest wszechobecne. Ten patent używa progów do usuwania tematów poniżej minimum trafności. Inne systemy Google stosują progi do zaufania linków, znaczenia fraz, filtrowania spamu, pamięci reformulacji zapytań i limitów personalizacji. Przycinanie progowe jest kluczowym elementem filozofii projektowania Google: wydajne, ograniczone, kontrolowane trafnością systemy, które nie gromadzą szumu.
5. Ten patent nie dotyczy SEO – ale logika jest przenośna. Ten patent wprost opisuje systemy dialogowe. Nie opisuje rankingu stron, indeksowania, oceny autorytetu tematycznego ani oceny stron. Jednak mechanizmy leżące u jego podstaw – modelowanie grafowe, ważone krawędzie, zanik, wzmacnianie – są spójne z tym, jak Google modeluje informacje w swoich innych systemach. Choć nie jest to bezpośredni dowód na mechanizmy SEO, wpisuje się w szerszą filozofię projektowania systemów Google.
Wnioski strategiczne
Co potwierdza ten patent
- Google preferuje modelowanie kontekstowe oparte na grafach
- Trafność jest ciągła i z czasem zanika
- Relacje kumulują siłę
- Współwystępowanie ma znaczenie
- Utrzymywanie kontekstu jest stopniowe, nie binarne
- Systemy są kontrolowane progami i przycinane
Co sugeruje (warstwa interpretacji)
- Wzmacnianie tematów ma prawdopodobnie większe znaczenie niż jednorazowe omówienie
- Powtarzające się semantyczne współwystępowanie może wzmacniać autorytet kontekstowy
- Izolowane węzły są słabsze niż połączone klastry
- Utrzymywanie treści może zapobiegać efektom zaniku
- Naturalne przejścia mogą lepiej wpisywać się w modelowanie kontekstowe
To jest ekstrapolacja. Nie bezpośrednie twierdzenie.
Kluczowa obserwacja
Najważniejszy wniosek architektoniczny tego patentu:
Systemy Google są zaprojektowane tak, by myśleć w ważonych, zanikających, relacyjnych grafach – nie w słowach kluczowych, nie w izolowanych stanach, nie w statycznych klasyfikacjach.
Ten patent to kolejne potwierdzenie, że:
Trafność = f(czas, relacje, wzmacnianie, progi)
Nie tylko obecność.