
Google Patent US10268680B2, invented by Piotr Tąkiel - a Polish Senior Software Engineer at Google - introduces a sophisticated system for managing human-to-computer dialogues. Its primary innovation: a dynamic "contextual data structure" that maintains and manages conversation topics, understands their semantic relationships, and tracks their temporal relevance. Reading this patent through an SEO lens reveals striking parallels with how topical authority may be evaluated in search.
General Information
Patent Metadata
- Patent ID: US10268680B2
- Grant Date: April 23, 2019
- Inventor: Piotr Tąkiel (Polish Senior Software Engineer at Google)
- Applicant: Google LLC, Mountain View, CA
- Official Title: "Context-aware human-to-computer dialog"
- Core Innovation: Contextual data structure as a dynamic memory framework for conversation topic management
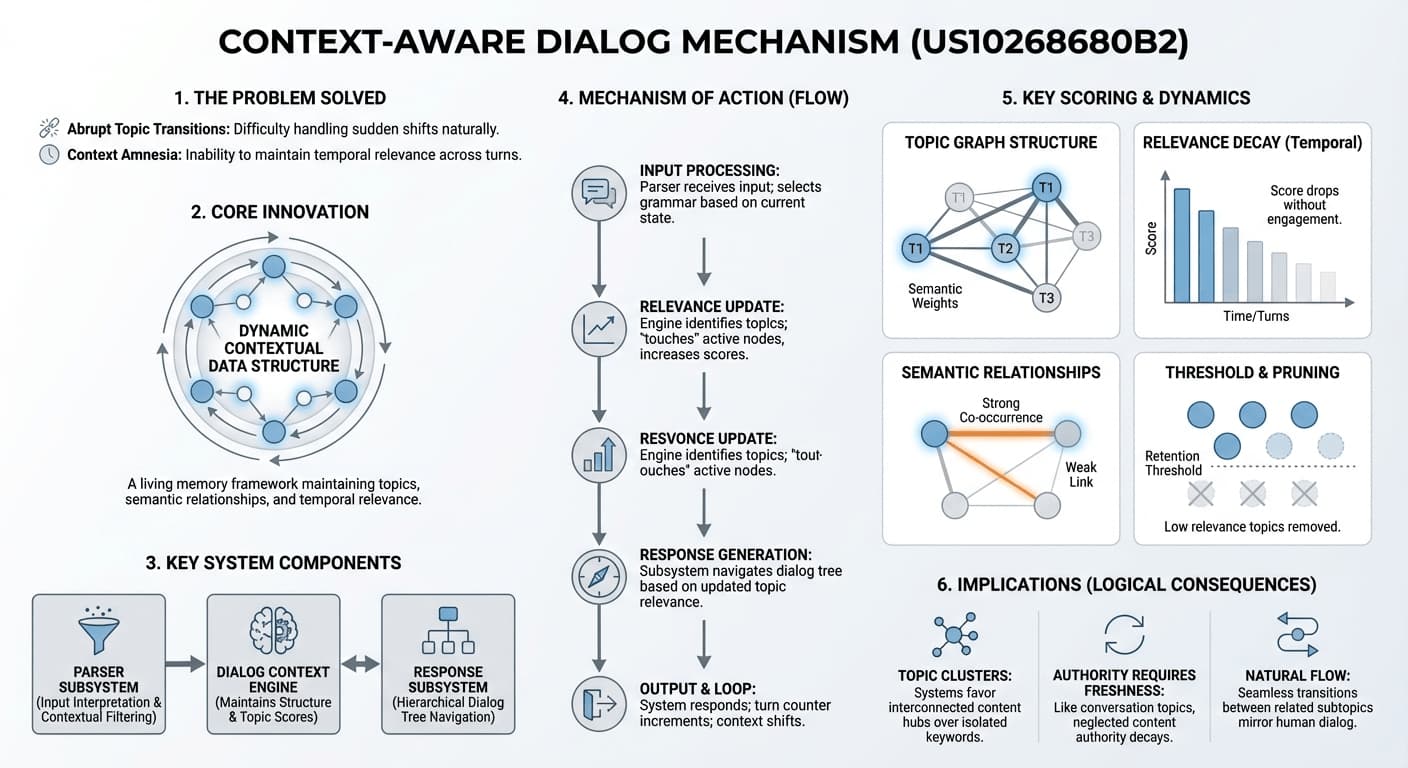
Patent Overview and Core Innovation
The patent addresses one of the fundamental challenges in conversational AI: handling abrupt topic transitions naturally and efficiently. When a user suddenly shifts from discussing one subject to another - and then back again - a naive system loses context, repeats itself, or asks redundant clarifying questions.
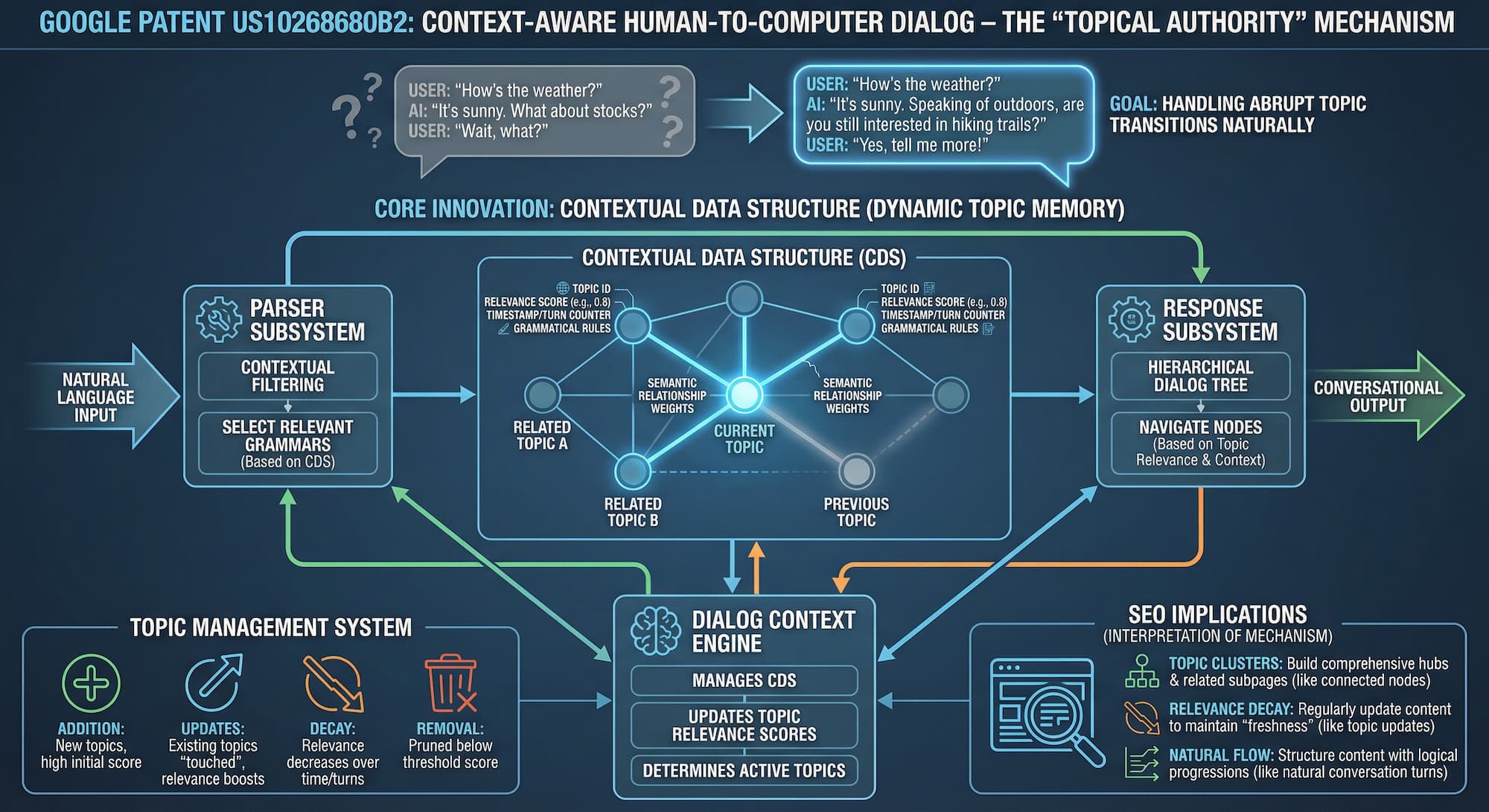
The system's solution is the "contextual data structure" - a memory framework implemented as an undirected graph. This graph continuously tracks which topics are active in a conversation, how strongly related those topics are to each other, and how recently each topic was referenced. Topics that go unmentioned gradually lose relevance; topics that are repeatedly co-referenced strengthen their semantic connections.
The core insight of the patent: relevance is not binary (relevant/irrelevant) but scored, time-sensitive, and relationship-dependent. A topic does not become instantly irrelevant when the conversation moves on - it decays, and can be revived. This is the mechanism the system uses to understand "what we were talking about."
Technical Architecture and Operation
The system operates through several interconnected components that work together to process, understand, and respond to natural language inputs:
Parser Subsystem
Serves as the initial processing layer, interpreting natural language inputs. It employs contextual filtering to select relevant grammars from a larger grammar database - dynamically, based on the current conversation state. The grammar rules applied depend on what topics are currently active.
Response Subsystem
Manages conversation flow through a hierarchical dialog tree. Each node represents a specific conversation process; parent-child relationships reflect the natural progression of dialogue. The system navigates between nodes based on topic relevance and current conversation context.
Dialog Context Engine
The core of the system. Maintains the contextual data structure, manages topic relevance scores, and continuously updates the conversation state. It determines which topics are currently active and relevant - the "working memory" of the entire dialog system.
Key Technical Components
1. Contextual Data Structure
The structure is implemented as an undirected graph. This is not a simple list - it is a relational network where topics are connected by semantic similarity, and each node carries rich metadata about its current state in the conversation.
Each node in the graph contains:
- Topic identifier - what the topic is
- Relevance score - how currently active/important this topic is
- Timestamp or conversation turn counter - when this topic was last referenced
- Associated grammatical rules - which parsing rules apply in this topic context
- Semantic relationship weights - how strongly this topic connects to others in the graph
Edges between nodes represent semantic relationships. Two topics that frequently co-occur in conversation develop stronger edge weights over time.
2. Relevance Scoring Mechanism
The system employs a multi-factor scoring algorithm. A topic's relevance score is not static - it is recalculated continuously based on several inputs:
Temporal Proximity
How recently a topic was discussed. A topic mentioned two turns ago scores higher than one mentioned twenty turns ago.
Conversation Turns
The number of exchanges since a topic was last mentioned. More turns elapsed = lower relevance score.
Semantic Relationships
The strength of connection to currently active topics. A related topic can maintain higher relevance even without being directly mentioned.
Two additional factors complete the scoring formula: topic persistence (how long a given topic naturally remains relevant in conversations of this type) and threshold values (minimum scores below which topics are pruned from active consideration entirely).
3. Grammar Selection and Application
The system implements a two-stage grammar processing approach that connects topic relevance directly to language parsing:
Stage 1: Contextual Filtering
- Evaluate current conversation context
- Identify relevant topics from contextual data structure
- Select appropriate grammar rules based on topic relevance scores
Stage 2: Grammar Application
- Apply selected grammars to parse natural language input
- Generate multiple possible interpretations
- Rank interpretations based on contextual relevance
4. Topic Management System
Topics are not simply "active" or "inactive." The system manages a continuous lifecycle for every topic in the conversation:
- Addition: New topics are added with high initial relevance scores when first introduced.
- Updates ("touching"): Existing topics are refreshed when referenced, resetting or boosting their relevance scores.
- Decay: Topic relevance naturally decreases over time and conversation turns, without any explicit action.
- Removal: Topics that fall below a threshold relevance score are pruned from the active structure entirely.
5. Semantic Relationship Processing
The system identifies topic connections through conversation context, strengthens relationships between frequently co-occurring topics, adjusts relationship weights based on conversation patterns, and uses these semantic relationships to influence topic relevance scores. A topic you haven't mentioned in ten turns may still be considered relevant if you're actively discussing a closely related topic.
The dialog tree itself is maintained through root node handling of new conversation threads, child node creation for specific conversation contexts, dynamic node relationship updates based on topic shifts, and preservation of conversation history for context maintenance. These components create a robust system capable of maintaining coherent conversations even when topics shift abruptly.
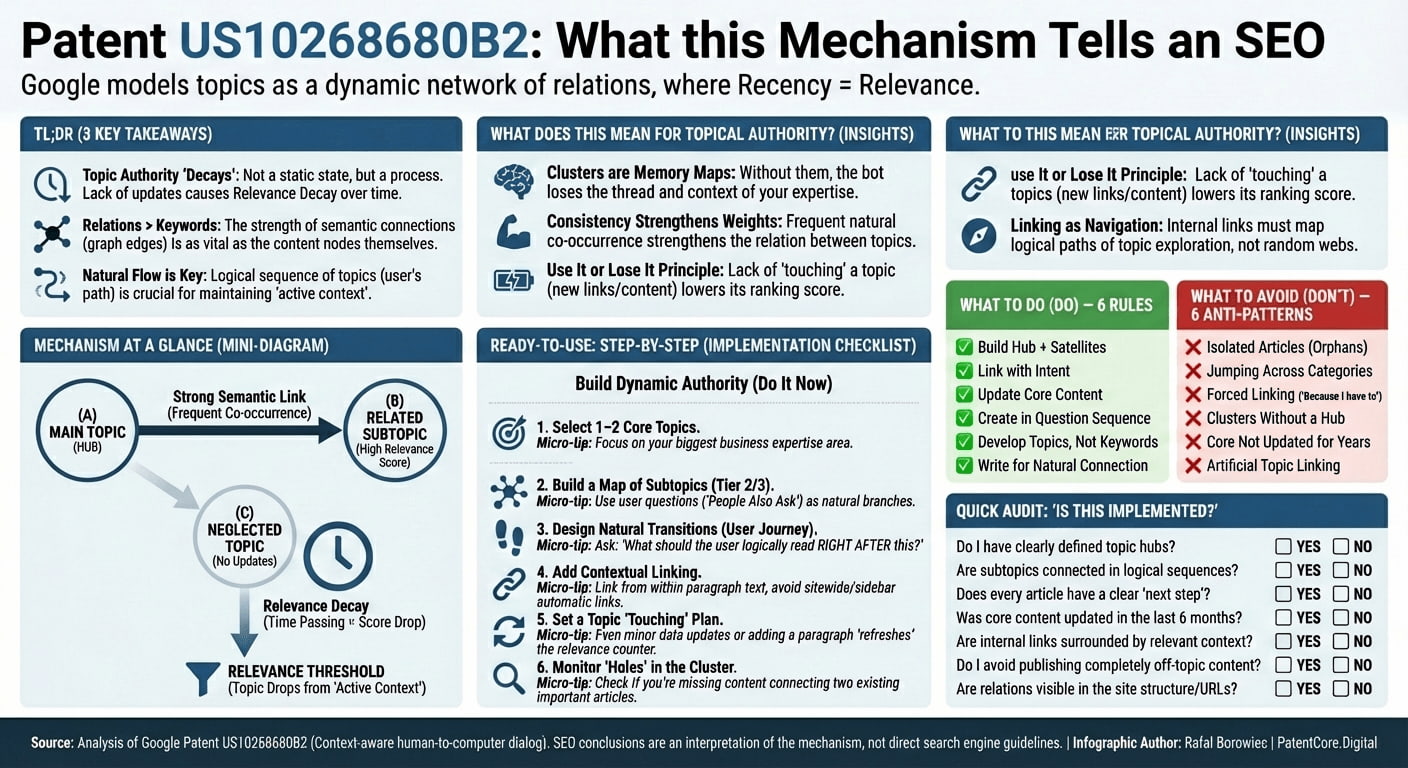
SEO Implications of the Patent's Technology
Important Note About These SEO Recommendations
Patent US10268680B2 specifically describes a system for managing topics in human-computer conversations. It does not directly address website content or SEO practices. However, by understanding how Google approaches topic relationships and relevance in conversations, we can make educated guesses about how similar principles might apply to website content and SEO.
The following recommendations are interpretations based on the patent's concepts - not direct instructions from Google. They represent my analysis of how Google's approach to conversational topic management might translate to content organization and search.
Content Relationship Understanding
The patent reveals how Google may understand relationships between content topics - similar to how it manages conversation topics. This has several important implications for how pages across a website are understood in relation to each other.
Example: If you have a website about cameras, Google might now better understand when you naturally transition between related topics like "DSLR cameras" → "camera lenses" → "lens filters", even when these topics appear on different pages. The contextual data structure described in the patent suggests Google can maintain these topical relationships and their relevance over time.
Topic Authority and Relevance Decay
The patent's relevance scoring mechanism provides insights into how Google might evaluate topical authority. The decay mechanism is particularly striking: a topic that receives no new "touches" (references, updates, related content) gradually loses its relevance score in the conversation. Apply this to a website, and the parallel becomes clear.
Practical example: If you publish comprehensive content about "digital photography", but then don't update or expand on that topic for an extended period while focusing on other subjects, your topical authority might "decay" - similar to how the patent handles topic relevance in conversations. This suggests the importance of consistently maintaining and updating content within your core topic areas.
Natural Content Flow
The patent's conversation management system suggests Google values natural topic transitions. Rather than creating isolated pages targeting different keywords, structuring content like a natural conversation - where each page logically leads to the next - may mirror how the patent handles conversation flows.
Consider the difference between a website with ten disconnected keyword-targeted pages versus one organized around a clear topical progression: Photography basics → Camera types → Specific camera reviews → Accessories → Techniques. The second mirrors how the patent's dialog tree works: each node naturally connects to related nodes, and the system navigates between them based on relevance and relationship strength.
Strategic SEO Recommendations
Build Topic Clusters
Create comprehensive hub pages for main topics and develop related subtopic pages that naturally connect to the hub. Use internal linking to reinforce topic relationships - mirroring the edges in the patent's undirected graph.
Hub Page
Comprehensive guide to "Digital Photography" - the high-relevance root node from which all related topics branch.
Connected Subtopics
Camera types and recommendations → Photography techniques → Post-processing tutorials. Each flows naturally from the main topic.
Semantic Edges
Internal links between subtopics that frequently co-occur (e.g., "camera lenses" ↔ "lens filters") reinforce relationship weights in the content graph.
Maintain Topic Freshness
The patent's decay mechanism makes this a strategic imperative: regularly update core topic content, add new relevant subtopics, and keep internal linking structures current. A practical implementation is to set up a content calendar ensuring regular updates to your most important topic clusters - preventing "topic decay" as described in the patent.
This is not about changing content for the sake of it. It is about signaling to Google that a topic remains actively maintained and authoritative, the equivalent of "touching" a topic node in the conversation graph to refresh its relevance score.
Create Natural Topic Transitions
Use logical content progressions, include contextual internal links, and develop content that anticipates user questions - the way a coherent conversation naturally leads from one topic to the next.
Example structure: "DSLR Cameras" article → "Understanding Camera Lenses" (natural next topic) → "Choosing the Right Lens for Your DSLR" (logical progression). Each page earns its place in the sequence by being the natural continuation of what came before.
What to Avoid
Isolated Content Creation
❌ Don't: Create standalone pages targeting keywords without topical connection.
✓ Instead: Ensure each new piece of content connects logically to your existing topic clusters. Example of what not to do: having a photography website and suddenly creating an isolated page about "best coffee makers" just because it has search volume.
Artificial Topic Relationships
❌ Don't: Force connections between unrelated topics.
✓ Instead: Focus on building genuine topical expertise in related areas. Bad example: trying to connect "camera reviews" to "weight loss tips" just because both topics are popular.
Neglecting Content Maintenance
❌ Don't: Let core topic content become outdated.
✓ Instead: Regularly update and expand your topic clusters. Poor practice: having a 2019 "Ultimate Guide to Digital Cameras" that hasn't been updated since publication - a topic node in decay.
Future Strategic Considerations
Topic Authority Development
Focus on building comprehensive coverage of core topics. Develop content that demonstrates deep expertise. Maintain consistent topic focus over time - not as a one-time effort but as an ongoing commitment that keeps relevance scores high.
Content Architecture Planning
Design website structure around natural topic relationships. Plan content development to support topic cluster growth. Create clear topical pathways through your site - mirroring the dialog tree structure where each node naturally leads to its children.
User Journey Mapping
Understand how users naturally move between topics. Create content that supports natural topic exploration. Anticipate and answer related questions - the way the patent's dialog tree anticipates and handles natural conversational progressions.
Content Freshness Strategy
Develop systems for regular content updates. Monitor topic relevance across your site. Plan for continuous topic expansion and refinement - the SEO equivalent of the patent's topic "touching" mechanism that resets and boosts relevance scores.
The SEO Takeaway
SEO success will increasingly depend on building genuine topic expertise and creating content that naturally flows between related subjects - similar to how human conversations progress.
- Topic clusters beat isolated pages - interconnected content mirrors the patent's semantic relationship graph and may signal stronger topical authority
- Relevance decays without maintenance - regular content updates are not optional; they are the mechanism that keeps topical authority scores high
- Natural transitions matter - content should flow logically between topics, not jump between disconnected subjects
- Semantic connections compound - the more strongly related your pages are to each other, the higher the implicit relevance of each page within the cluster
- Avoid context loss - just as the dialog system penalizes context breaks, abrupt topic changes or disconnected content may undermine perceived authority
The focus should be on developing comprehensive, interconnected content structures that demonstrate clear topical authority and maintain relevance over time. Not keyword targeting - topic architecture.

For Those Who Want to Understand This Patent Even Better
1. Context Is a Dynamic, Scored Structure - Not a Static State
The patent introduces a contextual data structure implemented as an undirected graph. Conversation context is not binary (active/inactive), not linear, and not instantly reset when a topic changes. Instead, it is scored, time-sensitive, relationship-dependent, and continuously recalculated.
Each topic node contains:
- A relevance score
- A timestamp or turn counter
- Semantic relationship weights to other nodes
- Associated grammar rules
The core principle: relevance decays gradually, not instantly. This alone is one of the most powerful architectural signals in the patent.
2. Relevance Is Multi-Factor and Continuous
Topic relevance is mathematical and cumulative, not heuristic guessing. It depends simultaneously on multiple inputs:
- Temporal proximity - how recently the topic was referenced
- Number of turns - how many exchanges have passed since the last mention
- Strength of semantic connections - relationship weights to currently active topics
- Topic persistence characteristics - how long this type of topic naturally remains relevant
- Threshold pruning rules - minimum scores below which a topic is removed from active consideration
A topic can remain relevant even if not directly mentioned - if it is semantically connected to currently active topics. This is crucial: presence is not required for relevance.
3. Relationships Strengthen Through Co-Occurrence
Edges between topics are weighted. When topics frequently co-occur, their relationship weight increases - and their mutual ability to revive each other's relevance increases along with it. The system learns topic proximity patterns over time.
This is not just storage. It is adaptive semantic modeling. The graph is not a snapshot - it is a living structure that learns from the conversation.
4. Grammar Selection Is Context-Gated
Parsing is not universal. Grammar rules are selected based on active topics, relevance thresholds, and the current context graph state. The practical consequence: the same phrase may be parsed differently depending on which topics are currently active in the contextual data structure. Interpretation of input is directly dependent on contextual graph activation - the system reads language through the lens of what it currently "knows" is relevant.
5. Topics Have a Lifecycle
Each topic moves through four distinct stages: introduction (high initial relevance score upon first mention), touching (score refresh when referenced again), decay (gradual relevance reduction over time and turns), and pruning (removal when score falls below threshold). The system is designed to avoid abrupt context loss while still preventing infinite memory accumulation. This is controlled forgetting - not arbitrary deletion, but a principled mechanism for keeping the active context both current and bounded.
Confrontation With Broader Knowledge From Other Google Patents
Confronting this patent with patterns seen across other Google systems - Navboost, phrase-based indexing, quality scoring systems, entity-based retrieval, query chains, session-based ranking - reveals consistent architectural philosophy beneath them all.
1. Graph-Based Modeling Is a Recurring Theme. This patent's undirected graph strongly aligns with entity-based indexing systems, the Knowledge Graph, phrase-based indexing, document-topic graphs, and link-based scoring systems. Google consistently models information as nodes + weighted edges + scoring functions + decay mechanisms. This is not isolated - it is architectural philosophy that repeats across systems.
2. Relevance Decay Mirrors Freshness and Query-Chain Patents. The decay mechanism parallels query recency scoring, historical click models, session-based search context, and Navboost-like reinforcement systems. Across patents, Google repeatedly boosts frequently reinforced elements, gradually reduces weight of inactive elements, and uses thresholds for pruning. This dialog patent fits precisely into that pattern.
3. Co-Occurrence Strengthening Mirrors Phrase-Based Indexing. Earlier Google patents describe phrases gaining importance based on co-occurrence frequency, documents being connected via shared phrases, and term relationships influencing scoring. This dialog system does the same - but for conversation topics. The principle is consistent across contexts: repeated association strengthens relationship weight.
4. Threshold-Based Pruning Is Everywhere. This patent uses thresholds to remove topics below a relevance minimum. Other Google systems apply thresholds to link trust, phrase significance, spam filtering, query reformulation memory, and personalization limits. Threshold pruning is a core element of Google's design philosophy: efficient, bounded, relevance-controlled systems that don't accumulate noise.
5. This Patent Is Not About SEO - But the Logic Is Portable. This patent explicitly describes dialog systems. It does not describe website ranking, indexing, topical authority scoring, or page evaluation. However, the underlying mechanics - graph modeling, weighted edges, decay, reinforcement - are consistent with how Google models information across its other systems. While not direct evidence for SEO mechanisms, it fits the broader ecosystem of Google's scoring philosophy.
Strategic Conclusions
What This Patent Confirms
- Google prefers graph-based contextual modeling
- Relevance is continuous and decays over time
- Relationships compound in strength
- Co-occurrence matters
- Context persistence is gradual, not binary
- Systems are threshold-controlled and pruned
What It Suggests (Interpretation Layer)
- Topic reinforcement likely matters more than one-time coverage
- Repeated semantic co-occurrence may strengthen contextual authority
- Isolated nodes are weaker than interconnected clusters
- Maintenance may prevent decay effects in various systems
- Natural transitions may align better with contextual modeling
This is extrapolation. Not direct claim.
The Deep Insight
The most important architectural insight of this patent:
Google systems are designed to think in weighted, decaying, relational graphs - not keywords, not isolated states, not static classifications.
This patent is another confirmation that:
Relevance = f(time, relationships, reinforcement, thresholds)
Not just presence.