
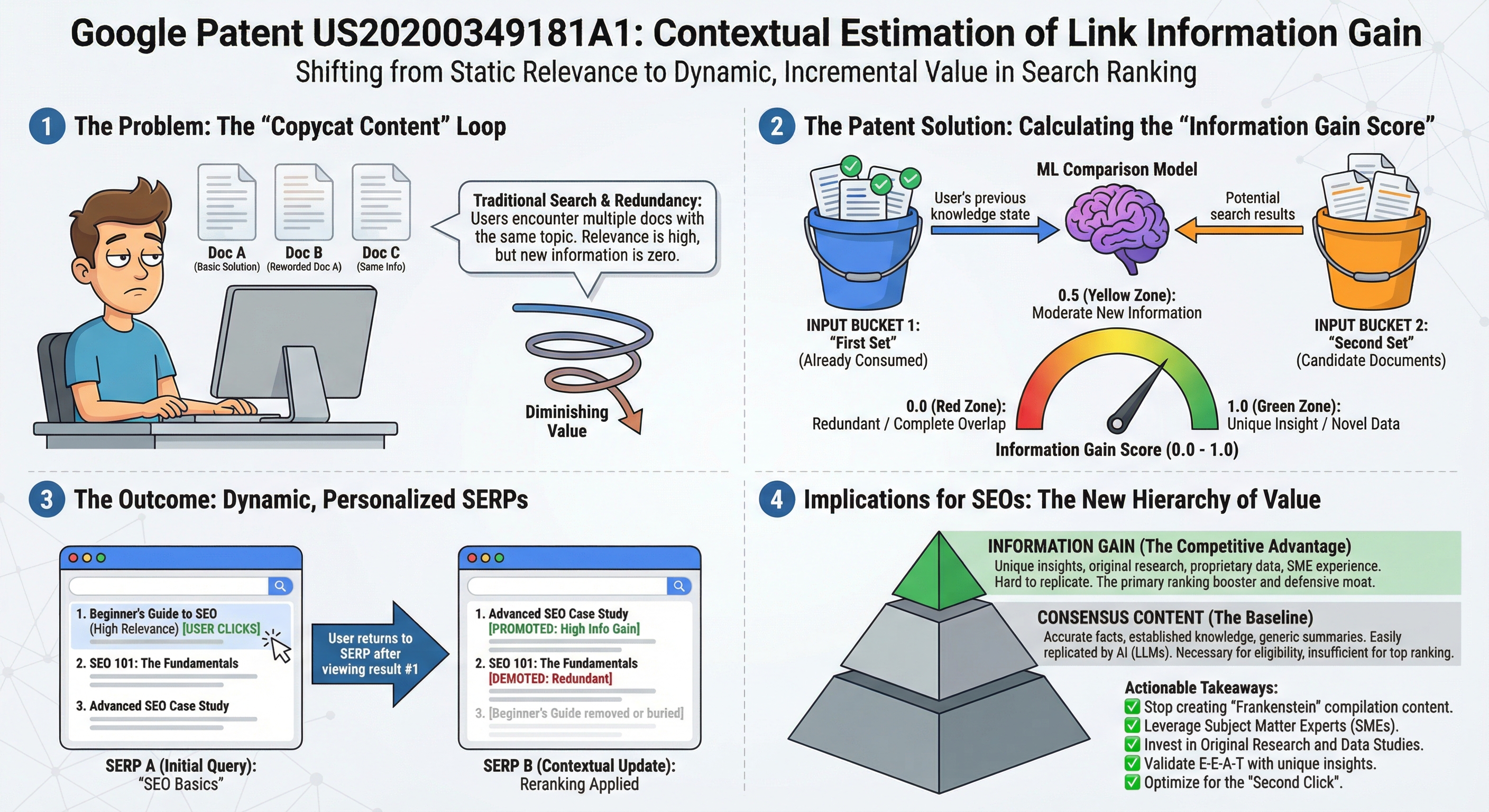
Patent Google US20200349181A1 opisuje system obliczania Information Gain Score - wartości uczonych maszynowo, mierzących, ile unikalnych informacji dokument wnosi ponad to, co użytkownik już przeczytał. Patent ten nadaje algorytmiczną moc zasadzie, że treść musi naprawdę informować, a nie jedynie powtarzać to, co już istnieje.
Informacje ogólne
Metadane patentu
- ID patentu: US20200349181A1
- Data publikacji: 5 listopada 2020
- Data przyznania: 7 czerwca 2022 (US11354342B2)
- Wynalazcy: Victor Carbune, Pedro Gonnet Anders
- Zgłaszający: Google LLC, Mountain View, CA
- Oficjalny tytuł: „Contextual estimation of link information gain"
Streszczenie
Patent opisuje techniki wyznaczania Information Gain Score dla dokumentów interesujących użytkowników i prezentowania informacji na podstawie tych wyników. Kluczowa innowacja odpowiada na fundamentalny problem w wyszukiwaniu: gdy wiele dokumentów dotyczy tego samego tematu, wiele z nich zawiera podobne lub redundantne informacje, zmniejszając wartość dla użytkowników, którzy zapoznali się już z pokrewnymi treściami.
Kluczowa koncepcja jest prosta: Information Gain Score dla danego dokumentu wskazuje dodatkowe informacje zawarte ponad to, co znajdowało się w dokumentach wcześniej przeglądanych przez użytkownika. Umożliwia to wyszukiwarkom i automatycznym asystentom priorytetyzowanie naprawdę unikalnych i wartościowych treści nad materiałem redundantnym.
Adresowany problem
Wyzwanie treści kopiujących
Użytkownicy często napotykają wiele dokumentów na ten sam temat z podobnymi informacjami. Po zapoznaniu się z jednym dokumentem kolejne podobne dokumenty oferują malejącą wartość - tymczasem tradycyjny ranking skupia się na trafności do zapytania, a nie na przyrostowej wartości informacyjnej dla konkretnego użytkownika.
Wyobraź sobie użytkownika szukającego „naprawa komputera" i otrzymującego 10 dokumentów, wszystkie wymieniające te same podstawowe kroki. Po przeczytaniu pierwszego artykułu kolejne dziewięć dostarcza zasadniczo zerowej wartości dodanej. A jednak wszystkie dziesięć może plasować się równie dobrze na tradycyjnych sygnałach trafności.
Patent bezpośrednio adresuje tę lukę. Jak wprost stwierdza: „chociaż dwa dokumenty dotyczące tego samego tematu mogą być trafne dla zapytania lub zainteresowania użytkownika, użytkownik może być mniej zainteresowany przeglądaniem drugiego dokumentu po zapoznaniu się z tymi samymi lub podobnymi informacjami w pierwszym dokumencie."
Kluczowe cechy techniczne
1. Zarządzanie zbiorami dokumentów
System utrzymuje przez cały czas dwa odrębne zbiory dokumentów. Pierwszy zbiór zawiera dokumenty już zaprezentowane użytkownikowi, które dzielą wspólny temat - ich informacje zostały wyekstrahowane i pokazane, a dokumenty są śledzone w bazie danych użytkownika. Drugi zbiór zawiera dokumenty kandydackie związane z tym samym tematem, które nie zostały jeszcze zaprezentowane - są one oceniane pod kątem Information Gain Score i mogą być przepisywane na podstawie tych wyników.
2. Obliczanie Information Gain Score
System używa modeli uczenia maszynowego do oceny wartości informacyjnej. Oba zbiory dokumentów są przekazywane do modelu - reprezentowane jako pełna treść, wektory semantyczne, embeddingi lub bag-of-words - a model generuje pojedynczy wynik między 0.0 a 1.0.
Wynik: 0.0
Brak nowych informacji - całkowite pokrycie z już przyswojonych treści
Wynik: 0.5
Umiarkowane nowe informacje - częściowe pokrycie, pewna unikalna treść
Wynik: 1.0
Całkowicie unikalne informacje - brak pokrycia z przyswojonych treści
Preferowaną metodą reprezentacji są semantyczne wektory cech i embeddingi, które pozwalają modelowi identyfikować pokrycie informacyjne nawet gdy treść jest przeformułowana. Obsługiwane są również reprezentacje bag-of-words i histogramowe, przy czym pełna treść dokumentu jest opcją najmniej efektywną.
3. Trenowanie modelu uczenia maszynowego
Model jest trenowany z użyciem dwóch metod. W pierwszej, ludzcy kuratorzy czytają pary dokumentów <d1, d2> i przypisują subiektywne wyniki Information Gain Score w skali 0.0 do 1.0 - odpowiadając zasadniczo na pytanie „Ile dodatkowych informacji zdobyłem z d2 po przeczytaniu d1?". W drugiej, prawdziwym użytkownikom wyszukującym i przeglądającym dokumenty zadawane jest pytanie, czy dokument był pomocny czy redundantny w stosunku do tego, co już przeczytali, a ich odpowiedzi automatycznie etykietują przykłady treningowe.
Proces trenowania generuje pary dokumentów lub ich reprezentacje semantyczne, porównuje wyniki modelu z etykietami przypisanymi przez ludzi, oblicza błąd i aktualizuje wagi modelu poprzez gradient descent, aż model dokładnie przewiduje przyrost informacji.
4. Dynamiczny system przepisywania
Gdy użytkownik przesyła zapytanie, system początkowo rankinguje dokumenty według tradycyjnej trafności. Po zapoznaniu się przez użytkownika z pierwszym dokumentem, dokument ten przechodzi do „Pierwszego zbioru" i system przelicza Information Gain Score dla wszystkich pozostałych kandydatów - potencjalnie przepisując całą listę. Po każdym kolejnym wyświetlonym dokumencie wyniki są przeliczane ponownie, uwzględniając całą skumulowaną historię czytania.
Kluczowa obserwacja: Wyniki są kontekstowe i dynamiczne - przeliczane w miarę zmiany stanu wiedzy użytkownika. Ten sam dokument może mieć wysoki Information Gain Score dla jednego użytkownika i zerowy dla innego, który już przyswoił równoważne treści.
Metody implementacji
Metoda 1: Integracja z automatycznym asystentem
W sesji dialogowej asystent identyfikuje odpowiednie dokumenty, wybiera ten z najwyższym wynikiem na podstawie połączonej trafności i Information Gain, wyodrębnia kluczowe informacje i prezentuje je przez text-to-speech lub interfejs wizualny. Gdy użytkownik pyta „Co jeszcze znalazłeś?", asystent przelicza Information Gain dla pozostałych dokumentów i prezentuje ten z najwyższą wartością przyrostową.
Zapobiega to pojawianiu się redundantnych informacji w kolejnych turach konwersacji, redukuje liczbę tur dialogu potrzebnych do omówienia tematu i znacznie poprawia efektywność wyjścia audio - co jest krytyczne w interakcjach głosowych, gdzie powtarzanie jest szczególnie frustrujące.
Metoda 2: Interfejs wyników wyszukiwania
Po kliknięciu przez użytkownika wynik i powrocie do SERP, system aktualizuje listę rankingową poprzez przeliczenie Information Gain Score, przepisanie pozostałych dokumentów i potencjalne wykluczenie już skonsumowanych treści.
Początkowe wyniki wyszukiwania
- Rozwiązywanie problemów z oprogramowaniem
- Ogólna naprawa komputera
- Poradnik naprawy sprzętu
- Wskazówki dotyczące oprogramowania
Po wyświetleniu doc. 1
- Poradnik naprawy sprzętu [AWANSOWANY]
- Zaawansowane naprawy oprogramowania
- Ogólna naprawa komputera [ZDEGRADOWANY]
- Rozwiązywanie problemów - usunięty
Metoda 3: Inteligentne filtrowanie treści (kontekst audio)
Wyobraź sobie dwa dokumenty: pierwszy omawia Przyczynę A i Przyczynę B; drugi omawia Przyczynę B i Przyczynę C. Tradycyjny system powtórzyłby Przyczynę B przy prezentacji drugiego dokumentu. Patent opisuje rozwiązanie: system identyfikuje elementy informacyjne już przekazane, rozpoznaje Przyczynę B jako już zaprezentowaną i wyodrębnia tylko Przyczynę C do wyjścia TTS.
Efekt jest taki, że użytkownik słyszy Przyczynę A, Przyczynę B i Przyczynę C w kolejności - bez powtórzeń, bez straconego czasu i bez frustracji.
Komponenty architektury technicznej
System opisany w FIG. 1 patentu składa się z dwóch głównych komponentów. Po stronie klienta: mikrofon do wejścia głosowego, klient automatycznego asystenta (106), interfejs wyszukiwania (107) oraz wyjście wyświetlacza/głośnika. Po stronie serwera: zdalny automatyczny asystent (115), silnik wyszukiwania (120), silnik oceniania Information Gain (125), silnik adnotacji Information Gain (130) i baza danych dokumentów użytkownika (140).
Przepływ danych podąża wyraźną ścieżką: zapytanie użytkownika trafia do silnika wyszukiwania, który identyfikuje dokumenty kandydackie. Baza danych dokumentów użytkownika śledzi, które dokumenty zostały już skonsumowane. Silnik oceniania Information Gain oblicza wyniki dla nowych kandydatów względem skonsumowanych treści. Wynikające z tego uszeregowane lub wyselekcjonowane dokumenty są następnie prezentowane użytkownikowi przez interfejs asystenta.
Implikacje dla SEO
1. Śmierć „treści Frankensteina"
Tradycyjny podręcznik SEO od dawna zalecał wzięcie pięciu najwyżej rankowanych stron, wyodrębnienie najlepszych sekcji z każdej i połączenie ich w jeden „kompleksowy" artykuł. Efektem jest dłuższa treść - ale z zerowymi nowymi informacjami. Patent zapewnia Google algorytmiczną metodę do identyfikowania dokładnie tego rodzaju treści i jej degradowania, nawet gdy dobrze radzi sobie na tradycyjnych sygnałach trafności.
2. Information Gain jako sygnał rankingowy
Wyobraź sobie dziesięć stron rankowanych dla „wymiana baterii iPhone". Strony 1–5 wyjaśniają ten sam siedmiostopniowy proces. Strona 6 dodaje unikalne wskazówki dotyczące rozwiązywania problemów nieznajdujące się na stronach 1–5. W tym systemie Strona 6 może być promowana ponad Strony 2–5 mimo niższego tradycyjnego wyniku trafności - ponieważ dla użytkownika, który przeczytał już Stronę 1, oferuje najwyższą wartość przyrostową.
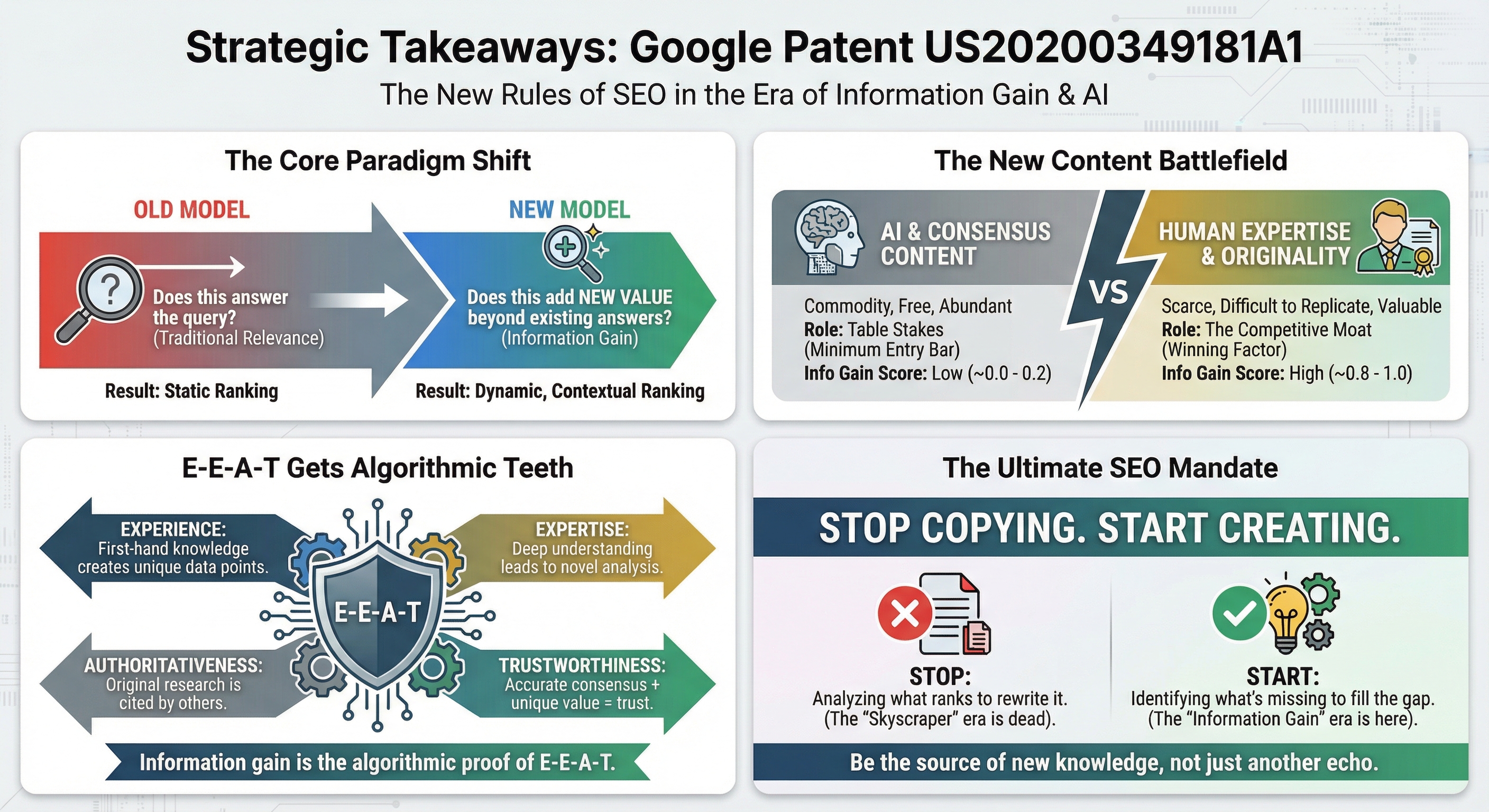
3. Treść konsensualna vs. Information Gain
Treść konsensualna (baseline)
Rzetelne informacje zgodne z ustalonym eksperckim konsensusem. Rola: minimalny próg kwalifikowalności do rankingu.
Information Gain (przewaga)
Unikalne spostrzeżenia wykraczające poza konsensus, oryginalne badania, perspektywy eksperckie niedostępne powszechnie. Rola: wyróżnik wśród kwalifikujących się treści.
Formuła jest prosta: Skuteczna treść SEO = Treść konsensualna (baseline) + Information Gain (przewaga). Bez konsensusu treść nie kwalifikuje się do rankingu. Bez Information Gain plasuje się poniżej stron oferujących unikalną wartość. Razem reprezentują optymalny potencjał rankingowy.
4. Powiązanie z E-E-A-T
Patent nadaje algorytmiczną moc E-E-A-T. Doświadczenie generuje unikalne spostrzeżenia, których konkurenci nie mogą powielić kopiując istniejące treści. Ekspertyza umożliwia nowatorskie analizy i interpretacje wykraczające poza powierzchowny konsensus. Autorytet jest budowany przez tworzenie oryginalnych treści, które inni cytują. Wiarygodność wyłania się z połączenia dokładnego konsensusu i unikalnych spostrzeżeń, których użytkownicy nie znajdą nigdzie indziej.
Jak ujmuje to patent: Information Gain to „wartość dodana do treści, która pochodzi z doświadczenia i ekspertyzy. Innymi słowy, nie jest to coś, co mogłoby zostać powielone przez LLM."
5. Zgodność z Helpful Content System
Wytyczne Google dotyczące pomocnych treści pytają: „Czy głównie streścisz to, co mówią inni, nie dodając wiele wartości?" To pytanie bezpośrednio adresuje Information Gain. Streszczanie istniejących treści generuje niskie wyniki; dodawanie realnej wartości - wysokie. Hipoteza - wsparta projektem patentu - jest taka, że Information Gain Score może być kluczowym komponentem algorytmu Helpful Content System.
6. Implikacje dla dynamicznych SERP
Tradycyjne SERP to statyczny ranking dla wszystkich użytkowników. SERP wzbogacone o Information Gain są spersonalizowane na podstawie indywidualnej historii przeglądania. Nowicjusz szukający „podstawy SEO" widzi treści dla początkujących. Ta sama osoba wracająca tydzień później może zobaczyć treści dla początkujących zdegradowane na rzecz materiałów zaawansowanych, których jeszcze nie przyswojyła.
Stwarza to konkretną okazję: treści zaprojektowane specjalnie dla scenariuszy „drugiego kliknięcia" - materiały dla użytkowników, którzy znają już podstawy - stają się odrębnym, możliwym do targetowania typem treści.
7. Głębokość treści vs. unikalność treści
Powszechnym błędem jest przekonanie, że dłuższe treści rankują lepiej. Logika tego patentu obala to założenie. Weź pod uwagę: Dokument A ma 3 000 słów obejmujących Tematy 1–5. Dokument B ma 1 500 słów obejmujących Tematy 1–3 oraz Tematy 6–7. Dla użytkownika, który przeczytał już o Tematach 1–5, Dokument A ma zerowy Information Gain mimo swojej długości, podczas gdy Dokument B - przy połowie liczby słów - oferuje znaczną nową wartość poprzez Tematy 6–7. Dokument B rankuje wyżej dla tego użytkownika.
Implikacja jest jasna: jeden akapit naprawdę nowatorskich spostrzeżeń wyprzedza trzy akapity redundantnych wyjaśnień.
Rekomendacje strategiczne dla specjalistów SEO
1. Przeprowadzaj audyty Information Gain
Zidentyfikuj docelowy temat, przeanalizuj dziesięć najwyżej rankowanych stron i zmapuj, jakie elementy informacyjne każda z nich obejmuje. Odróżnij „informacje konsensualne" - treści pojawiające się na większości lub wszystkich stronach - od prawdziwych luk, których nikt nie pokrywa. Twoje treści powinny w pełni adresować konsensus, skupiając kreatywną energię na wypełnianiu tych luk.
Przydatne podejście wspomagane AI: poproś LLM o napisanie kompleksowego artykułu na twój temat. Wynik reprezentuje niemal idealną treść konsensualną. Porównaj go ze swoim szkicem - to, co jest w wersji AI, to baseline; to, co jest tylko w twojej wersji, to twoja przewaga Information Gain.
2. Korzystaj z ekspertów dziedzinowych (SME)
Eksperci dziedzinowi posiadają wiedzę, która nie istnieje w żadnej opublikowanej treści - co oznacza automatyczny Information Gain. Pokaż im najwyżej rankowane treści i zapytaj, czego brakuje, co jest nieprawidłowe lub jaki niuans jest utracony. Przeprowadzaj wywiady, by pozyskać unikalne anegdoty i studia przypadków. Skorzystaj z ich dostępu do danych własnościowych - metryk firmy, opinii klientów, wewnętrznych badań - których konkurenci nie mogą pozyskać przez konwencjonalne badania.
Przegląd treści
Pokaż SME najwyżej rankowane treści. Zapytaj: „Czego brakuje?" „Co jest nieprawidłowe?" „Jaki niuans jest utracony?" Dokumentuj ich spostrzeżenia.
Treści oparte na wywiadach
Pozyskaj unikalne anegdoty i studia przypadków. Przykład: „Wypróbowaliśmy standardowe podejście, ale odkryliśmy, że..." - niemożliwe do wygenerowania przez LLM.
Dostęp do danych
SME często mają dane własnościowe - metryki firmy, opinie klientów, wyniki badań - niedostępne dla żadnego konkurenta opierającego się na publicznych źródłach.
3. Twórz oryginalne badania i dane
Oryginalne badania są z definicji unikalne - nie mogą być powielone przez konkurentów bez przeprowadzenia tych samych badań. Zapewnia to najbliższy gwarantowanemu Information Gain Score 1.0 dla konkretnych punktów danych. Rodzaje badań obejmują ilościowe ankiety klientów, jakościowe wywiady i studia przypadków, testy porównawcze produktów oraz coroczne branżowe studia benchmarkingowe. Jako dodatkowa korzyść, oryginalne badania przyciągają linki przychodzące od innych wydawców cytujących twoje dane.
4. Współpracuj między działami
Działy marketingu rzadko mają spostrzeżenia z pierwszej linii. Prawdziwe problemy klientów - i prawdziwy język klientów - pojawiają się w działach Obsługi Klienta, Sprzedaży oraz Produktu/Inżynierii. Obsługa klienta zna najczęstsze problemy, pytania, które klienci faktycznie zadają, oraz błędne przekonania, które nigdy nie są adresowane w treściach marketingowych. Sprzedaż zna obiekcje, czynniki decyzyjne i to, co mówią konkurenci. Inżynierowie znają szczegóły techniczne i błędy implementacyjne, które osoby z zewnątrz mogą jedynie zgadywać.
Zaplanuj kwartalne spotkania treści między działami z jednym pytaniem: „Co klienci pytają cię, czego nie ma dobrze opisanego w internecie?"
5. Używaj AI do identyfikowania konsensusu (nie do tworzenia treści)
LLM są trenowane na istniejących treściach. Z definicji mogą produkować tylko informacje konsensualne - nie mogą tworzyć Information Gain. To ograniczenie można przekształcić w narzędzie strategiczne: wygeneruj artykuł AI na swój temat, by uzyskać precyzyjny baseline tego, jak wygląda konsensus, a następnie skup ludzką energię wyłącznie na tym, czego AI nie mogła napisać.
Praktyczny test: Jeśli LLM może to napisać, to nie jest Information Gain. Jeśli LLM nie może tego napisać - bo pochodzi z twoich własnych danych, unikalnego doświadczenia lub oryginalnych badań - to JEST Information Gain.
6. Struktura treści pod kątem przyrostowej wartości
Użytkownicy mogą trafić na twoją stronę po przeczytaniu już artykułu konkurenta. Strukturyzuj treść, biorąc to pod uwagę. Krótko omów konsensus, by czytelnicy po raz pierwszy nie byli zagubieni, a następnie wyraźnie zasygnalizuj, gdzie twoje treści się wyróżniają: „Większość poradników zatrzymuje się tutaj. Oto czego nie opisują..." Następnie poświęć większość materiału swoim unikalnym spostrzeżeniom, wyraźnie oznaczonym jako nowe informacje.
7. Monitoruj Information Gain konkurencyjnie
Ustaw miesięczny rytm przeglądania dziesięciu najlepszych wyników dla twoich docelowych słów kluczowych i notuj wszelkie nowe informacje, których nie było tam 30 dni temu. Gdy konkurent publikuje nowe spostrzeżenia, nie kopiuj ich - odpowiadaj na nie. „Przetestowaliśmy te pięć strategii. Oto co faktycznie zadziałało" dodaje Information Gain na podstawie ich Information Gain, zamiast po prostu je echować.
8. Optymalizuj pod kątem scenariuszy „drugiego kliknięcia"
Projektuj treści wyraźnie dla użytkowników, którzy przyswoili już podstawy. Artykuły „Czego ci nie mówią" zakładają, że czytelnik już zna podstawy i skupiają się wyłącznie na zaawansowanych lub niuansowych kwestiach. Treści porównawcze zakładają, że czytelnik zna poszczególne opcje i zapewniają szczegółową analizę porównawczą wymagającą rzeczywistego testowania. Poradniki rozwiązywania problemów zakładają, że czytelnik wypróbował już standardowe rozwiązania i adresują przypadki brzegowe. Meta-analizy syntetyzują wyniki z wielu źródeł i dodają oryginalną interpretację.
9. Buduj dashboardy Information Gain
Systematycznie śledź swoje unikalne zasoby treści: własne studia badawcze, oryginalne zbiory danych, unikalne studia przypadków, spostrzeżenia wniesione przez SME na artykuł, przykłady specyficzne dla firmy jako procent treści, oryginalne ramy i metodologie oraz tematy omawiane wyłącznie przez twoją publikację. Ten dashboard identyfikuje, gdzie twoje treści wymagają odświeżenia Information Gain i demonstruje ROI z inwestowania w czas SME i oryginalne badania.
Dlaczego każdy specjalista SEO musi zrozumieć ten patent
1. Zmiana paradygmatu: od trafności do wartości
Stary model wyglądał tak: Zapytanie → Trafna treść → Ranking, z centralnym pytaniem „Czy to odpowiada na pytanie?". Nowy model dodaje dodatkową warstwę: Zapytanie → Trafna treść → Ocena Information Gain → Ranking, z pytaniem „Czy to wnosi wartość ponad istniejące odpowiedzi?". Sama trafność nie jest już wystarczająca - jest jedynie wymogiem wejścia.
2. Algorytmiczne wykrywanie jakości treści
Patent ujawnia, że Google dysponuje techniczną metodą wykrywania treści „kopiujących" - nie tylko wykrywania duplikatów, które istnieje od lat, ale nowatorską zdolność: wykrywanie pokrycia informacyjnego nawet gdy treść jest całkowicie przeformułowana. System używa semantycznego rozumienia do identyfikowania redundancji na poziomie znaczenia, nie słów. Spinning treści jest ewidentnie nieskuteczny wobec tego systemu. Jedyną drogą naprzód są naprawdę nowe informacje.
3. Personalizacja ścieżki użytkownika na skalę
Patent jest wczesnym planem dla spersonalizowanych SERP opartych na stanie wiedzy. Pierwszorazowy wyszukiwacz i powracający badacz przesyłający to samo zapytanie mogą zobaczyć zasadniczo różne wyniki. Treści muszą być zaprojektowane do obsługi użytkowników na określonych etapach ich wiedzy - nie tylko targetując słowo kluczowe, ale targetując to, gdzie użytkownik jest w swoim rozumieniu tematu.
4. Optymalizacja głosowa i pod asystentów staje się krytyczna
W kontekstach głosowych i asystentów, filtrowanie Information Gain nie jest miłym dodatkiem - jest niezbędne. Treści audio są liniowe; użytkownicy nie mogą skanować ani pomijać. Słyszenie tych samych informacji powtarzanych w wielu odpowiedziach asystenta jest wyjątkowo frustrujące. Patent specyficznie adresuje scenariusze TTS, sygnalizując, że optymalizacja głosowa i Information Gain są głęboko powiązane. Modularne, ekstrakowalne treści z wyraźną hierarchią informacyjną będą najlepiej funkcjonować w tych kontekstach.
5. Defensywne SEO staje się konieczne
Z tego systemu wyłania się nowe ryzyko konkurencyjne. Jeśli konkurent publikuje treści obejmujące wszystko, co obejmuje twój poradnik, plus dodatkowe unikalne tematy, użytkownicy, którzy przeczytali już twój poradnik, uznają, że treść konkurenta ma wysoki Information Gain względem ich istniejącej wiedzy. Twoja treść będzie wyglądać na zerowy Information Gain dla tych użytkowników - mimo że opublikowałeś jako pierwszy. Ciągłe ulepszanie treści i monitorowanie konkurencji stają się obowiązkowe, nie opcjonalne.
6. Potwierdza inwestycję w oryginalne badania
Historyczne pytanie - „Czy oryginalne badania są warte kosztu?" - ma teraz odpowiedź opartą na patencie: oryginalne badania produkują gwarantowany Information Gain, który jest udokumentowanym sygnałem rankingowym. Biznesowe uzasadnienie dla badania wartego 50 000 zł staje się mierzalne: unikalne treści, które rankują ponad wszystkimi konkurentami o podobnej trafności, dane cytowane w podsumowaniach AI, linki zwrotne od wydawców cytujących twoje wyniki oraz pozycjonowanie lidera myśli, które kumuluje się z czasem.
7. Implikacje wyścigu zbrojeń treści AI
Treści generowane przez AI są z definicji wysokie w konsensusie i zerowe w Information Gain. LLM nie mogą zawierać danych własnościowych, unikalnych doświadczeń ani nowatorskich badań - są trenowane na tym, co już istnieje. Treści eksperckich ludzi, z kolei, zawierają zarówno konsensusowy baseline, jak i unikalne spostrzeżenia, których żaden algorytm nie może wygenerować. W miarę jak AI sprawia, że treści konsensualne stają się bezpłatne i obfite, Information Gain staje się jedynym rzadkim zasobem i głównym wyróżnikiem rankingowym.
Spostrzeżenie strategiczne: Im bardziej AI upowszechnia tworzenie treści konsensualnych, tym cenniejsza staje się ludzka ekspertyza i oryginalne dane. Patent opisuje dokładnie mechanizm, za pomocą którego Google będzie nagradzać jedne i deprecjonować drugie.
Praktyczna lista kontrolna wdrożenia
Działania natychmiastowe
- Wylistuj swoje 10 najwyżej rankowanych artykułów; dla każdego zidentyfikuj, co jest unikalne vs. konsensualne; priorytetyzuj aktualizacje dla treści o niskich wynikach
- Zidentyfikuj ekspertów dziedzinowych w swojej organizacji; zmapuj ich ekspertyzę do tematów treści; zaplanuj wstępne spotkania
- Przejrzyj ostatnie treści 3 głównych konkurentów; zanotuj wszelkie unikalne informacje, które opublikowali; oceń, czy wyprzedzają cię w Information Gain
Wdrożenie krótkoterminowe
- Stwórz szablon wywiadu z SME; ustanów międzydziałowy proces wkładu treści; skonfiguruj system śledzenia Information Gain
- Zidentyfikuj 3 tematy, w których możesz stworzyć unikalną wartość; zaplanuj projekt oryginalnych badań lub analizy danych; opracuj briefy treści „czego brakuje"
- Wdróż śledzenie wzorców konsumpcji dokumentów; zaplanuj możliwości personalizacji, gdy staną się dostępne
Strategia długoterminowa
- Zamów lub przeprowadź swój pierwszy projekt oryginalnych badań; przeanalizuj własne dane pod kątem udostępnialnych spostrzeżeń; opracuj studia przypadków z doświadczeń klientów
- Edukuj pisarzy w zakresie koncepcji Information Gain; szkol redaktorów do identyfikowania i żądania unikalnych spostrzeżeń; dopasuj organizację do Information Gain jako priorytetu treści
- Zdefiniuj KPI Information Gain; śledź poprawę rankingów dla ulepszonych treści; monitoruj metryki zaangażowania i pozycjonowanie konkurencyjne
Wnioski SEO
Patent Google US20200349181A1 reprezentuje fundamentalną ewolucję w tym, jak wyszukiwarki oceniają i rankingują treści. Podczas gdy tradycyjne SEO skupiało się na trafności (czy to odpowiada na zapytanie?), nowoczesne SEO musi dodatkowo optymalizować pod kątem Information Gain (czy to wnosi wartość ponad istniejące odpowiedzi?).
- Treść konsensualna jest teraz wymogiem minimalnym - dokładne pokrycie to minimalny wymóg, nie przewaga konkurencyjna
- Information Gain to nowy wyróżnik - unikalne spostrzeżenia, oryginalne badania, perspektywy eksperckie będą coraz bardziej wyprzedzać treści wyłącznie konsensualne
- Kontekst użytkownika ma znaczenie - rankingi mogą stać się spersonalizowane na podstawie tego, co użytkownicy już przyswojili
- E-E-A-T uzyskuje algorytmiczną moc - patent zapewnia techniczną metodę nagradzania Doświadczenia i Ekspertyzy
- AI sprawia, że to jest ważniejsze - w miarę jak LLM upowszechniają treści konsensualne, ludzka ekspertyza staje się jedynym zrównoważonym fosem
Przestań tworzyć treści analizując to, co rankuje. Zacznij tworzyć treści identyfikując to, czego brakuje. Przyszłość SEO należy do wydawców, którzy mogą konsekwentnie dostarczać informacje, których użytkownicy nie mogą znaleźć nigdzie indziej.