
Google Patent US20200349181A1 describes a system for calculating Information Gain Scores - machine-learned values that measure how much unique information a document adds beyond what a user has already consumed. This patent provides algorithmic teeth to the principle that content must genuinely inform, not just repeat what already exists.
General Information
Patent Metadata
- Patent ID: US20200349181A1
- Publication Date: November 5, 2020
- Grant Date: June 7, 2022 (US11354342B2)
- Inventors: Victor Carbune, Pedro Gonnet Anders
- Applicant: Google LLC, Mountain View, CA
- Official Title: "Contextual estimation of link information gain"
Abstract
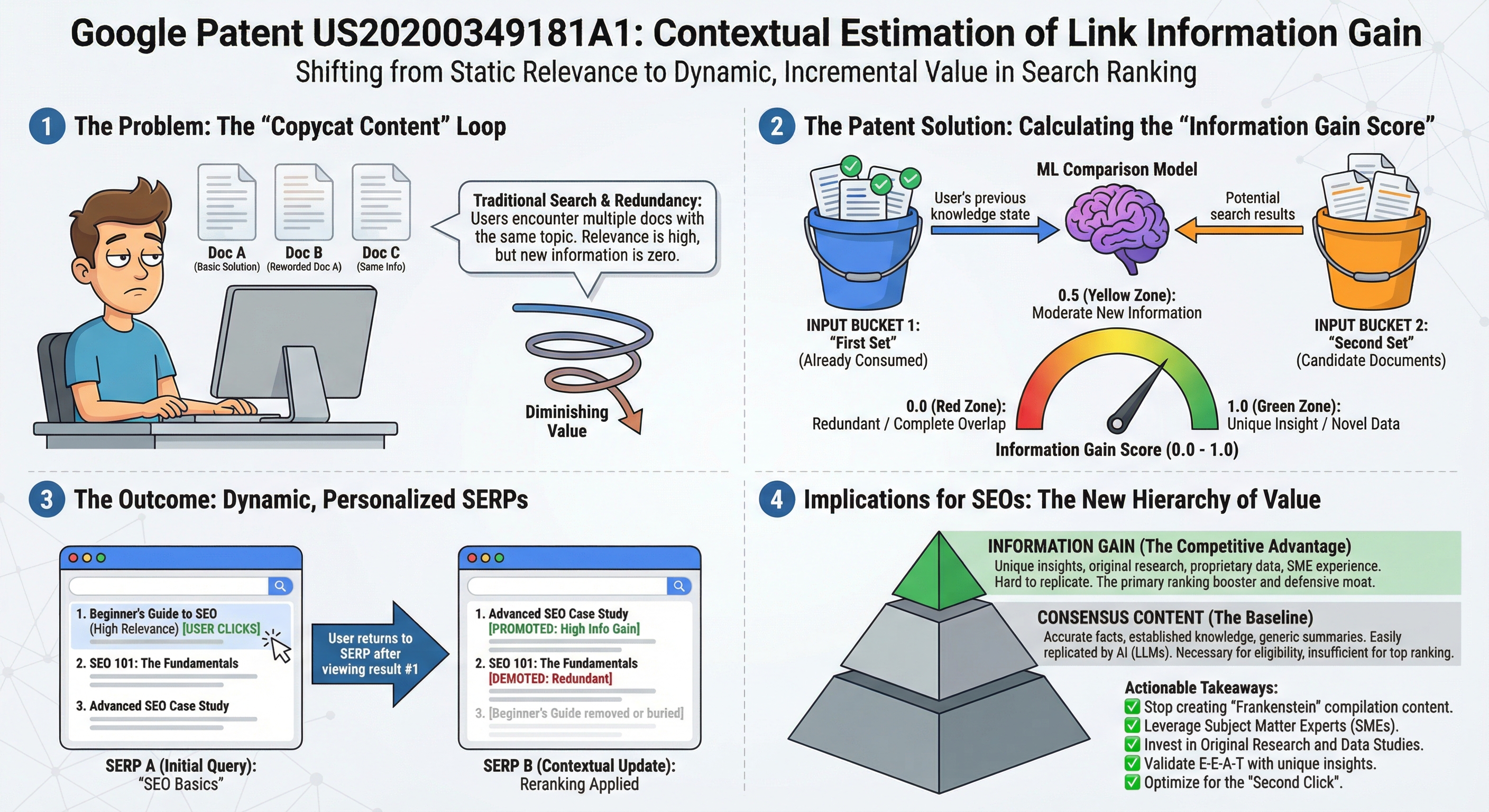
The patent describes techniques for determining an Information Gain Score for documents of interest to users and presenting information based on these scores. The core innovation addresses a fundamental problem in search: when multiple documents share a topic, many contain similar or redundant information, reducing value for users who have already consumed related content.
The key concept is straightforward: an information gain score for a given document indicates additional information included beyond what was contained in documents previously viewed by the user. This enables search engines and automated assistants to prioritize truly unique and valuable content over redundant material.
Core Problem Addressed
The Copycat Content Challenge
Users frequently encounter multiple documents on the same topic with similar information. After viewing one document, subsequent similar documents provide diminishing value - yet traditional ranking focuses on relevance to the query, not on incremental information value to a specific user.
Imagine a user searching "fix my computer" and receiving 10 documents all listing the same basic troubleshooting steps. After reading the first article, the next nine provide essentially zero additional value. Yet all ten may rank equally well on traditional relevance signals.
The patent directly addresses this gap. As it explicitly states: "although two documents that share a topic may be relevant to the request or interest of the user, the user may have less interest in viewing a second document after already viewing the same or similar information in a first document."
Key Technical Features
1. Document Set Management
The system maintains two distinct document sets at all times. The First Set contains documents already presented to the user that share a common topic - their information has been extracted and shown, and they are tracked in the user document database. The Second Set contains candidate documents related to the same topic that have not yet been presented - these are evaluated for information gain scores and may be reranked based on those scores.
2. Information Gain Score Calculation
The system uses machine learning models to evaluate information value. Both sets of documents are fed into the model - represented as full content, semantic vectors, embeddings, or bag-of-words - and the model outputs a single score between 0.0 and 1.0.
Score: 0.0
No new information - complete overlap with already-consumed content
Score: 0.5
Moderate new information - partial overlap, some unique content
Score: 1.0
Completely unique information - no overlap with consumed content
The preferred representation method is semantic feature vectors and embeddings, which allow the model to identify informational overlap even when content is reworded. Bag-of-words and histogram representations are also supported, with full document content being the least efficient option.
3. Machine Learning Model Training
The model is trained using two methods. In the first, human curators read document pairs <d1, d2> and provide subjective information gain scores on a 0.0 to 1.0 scale - essentially answering "How much additional information did I gain from d2 after reading d1?" In the second, real users searching and consuming documents are asked whether a document was helpful or redundant given what they had already read, with their responses automatically labeling training examples.
The training process generates pairs of documents or their semantic representations, compares the model's output to human-assigned labels, calculates error, and updates model weights via gradient descent until the model accurately predicts information gain.
4. Dynamic Reranking System
When a user submits a query, the system initially ranks documents by traditional relevance. After the user views the first document, that document moves to the "First Set" and the system recalculates information gain scores for all remaining candidates - potentially reranking the entire list. After each subsequent document is viewed, scores are recalculated again, considering the entire accumulated reading history.
Key insight: Scores are contextual and dynamic - recalculated as the user's knowledge state changes. The same document can have a high information gain score for one user and zero for another who has already consumed equivalent content.
Implementation Methods
Method 1: Automated Assistant Integration
In a dialog session, the assistant identifies responsive documents, selects the highest-scoring one based on combined relevance and information gain, extracts salient information, and presents it via text-to-speech or a visual interface. When the user asks "What else have you found?", the assistant recalculates information gain for remaining documents and presents the one with the highest incremental value.
This prevents redundant information from appearing across conversation turns, reduces the number of dialog turns needed to cover a topic, and significantly improves efficiency of audio output - which is critical for voice-based interactions where repetition is especially frustrating.
Method 2: Search Results Interface
After a user clicks a result and returns to the SERP, the system updates the ranking list by recalculating information gain scores, reranking remaining documents, and potentially excluding already-consumed content.
Initial Search Results
- Software Troubleshooting
- General Computer Repair
- Hardware Repair Guide
- Software Tips
After Viewing Doc 1
- Hardware Repair Guide [PROMOTED]
- Advanced Software Fixes
- General Computer Repair [DEMOTED]
- Software Troubleshooting - removed
Method 3: Intelligent Content Filtering (Audio Context)
Consider two documents: the first discusses Cause A and Cause B; the second discusses Cause B and Cause C. A traditional system would repeat Cause B when presenting the second document. The patent describes a solution: the system identifies information elements already conveyed, recognizes Cause B as already presented, and extracts only Cause C for the TTS output.
The result is that the user hears Cause A, Cause B, and Cause C in sequence - without repetition, without wasted time, and without frustration.
Technical Architecture Components
The system described in the patent's FIG. 1 consists of two main components. On the client side: a microphone for voice input, the Automated Assistant Client (106), a Search Interface (107), and display/speaker output. On the server side: the Remote Automated Assistant (115), Search Engine (120), Information Gain Scoring Engine (125), Information Gain Annotation Engine (130), and User Document Database (140).
The data flow follows a clear path: a user query enters the Search Engine, which identifies candidate documents. The User Document Database tracks which documents have already been consumed. The Information Gain Scoring Engine calculates scores for new candidates relative to consumed content. The resulting ranked or selected documents are then presented to the user through the assistant interface.
Implications for SEO
1. The Death of "Frankenstein Content"
The traditional SEO playbook has long recommended taking the top five ranking pages, extracting the best sections from each, and combining them into a single "comprehensive" article. The result is longer content - but with zero new information. This patent provides Google with an algorithmic method to identify exactly that kind of content and demote it, even when it performs well on traditional relevance signals.
2. Information Gain as Ranking Signal
Consider ten pages ranking for "iPhone battery replacement." Pages 1–5 all explain the same seven-step process. Page 6 adds unique troubleshooting tips not found in Pages 1–5. Under this system, Page 6 may be promoted above Pages 2–5 despite having a lower traditional relevance score - because for a user who has already read Page 1, it offers the highest incremental value.
3. Consensus Content vs. Information Gain
Consensus Content (Baseline)
Factually accurate information aligned with established expert consensus. Role: minimum threshold for ranking eligibility.
Information Gain (Advantage)
Unique insights beyond consensus, original research, expert perspectives not widely available. Role: differentiator among eligible content.
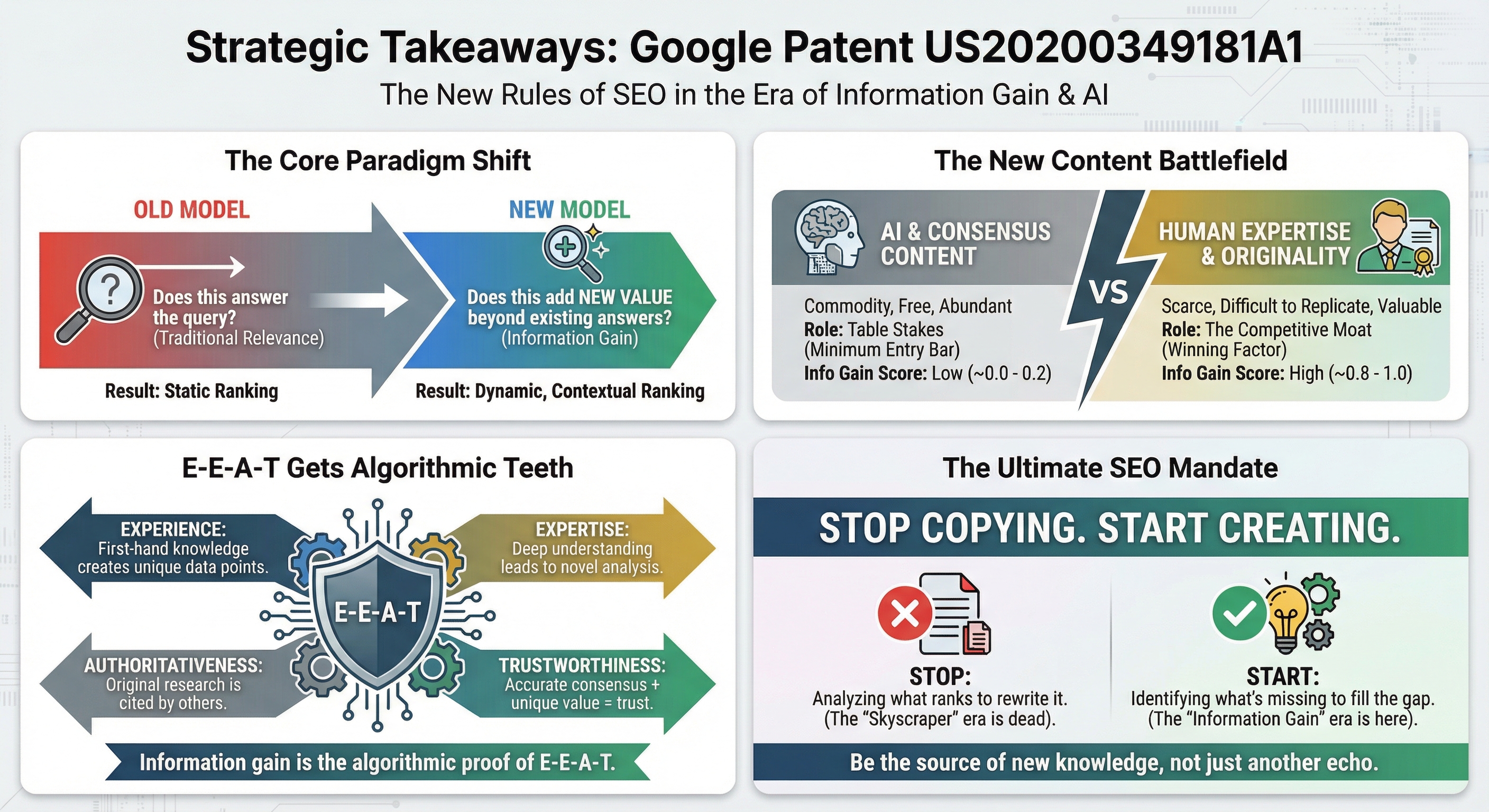
The formula is straightforward: Successful SEO Content = Consensus Content (baseline) + Information Gain (advantage). Without consensus, content is not eligible to rank. Without information gain, it ranks below pages offering unique value. Together, they represent optimal ranking potential.
4. E-E-A-T Connection
This patent provides algorithmic teeth for E-E-A-T. Experience produces unique insights that cannot be replicated by competitors copying existing content. Expertise enables novel analysis and interpretations that go beyond surface-level consensus. Authoritativeness is established by producing original content others reference. Trustworthiness emerges from the combination of accurate consensus and unique insights that users cannot find elsewhere.
As the patent frames it: information gain is "the value added to content that comes from experience and expertise. In other words, it's not something that could be replicated by an LLM."
5. Helpful Content System Alignment
Google's Helpful Content Guidelines ask: "Are you mainly summarizing what others have to say without adding much value?" This question directly addresses information gain. Summarizing existing content produces low scores; adding genuine value produces high ones. The hypothesis - supported by the patent's design - is that information gain scores may be a core component of the Helpful Content System algorithm.
6. Dynamic SERP Implications
Traditional SERPs are static ranking for all users. Information Gain-enhanced SERPs are personalized based on individual browsing history. A novice searching "SEO basics" sees beginner content. The same person returning a week later may see the beginner content demoted in favor of intermediate and advanced material they haven't yet consumed.
This creates a concrete opportunity: content specifically designed for "second-click" scenarios - material for users who already know the basics - becomes a distinct, targetable content type.
7. Content Depth vs. Content Uniqueness
A common misconception is that longer content ranks better. This patent's logic dismantles that assumption. Consider: Document A has 3,000 words covering Topics 1–5. Document B has 1,500 words covering Topics 1–3 plus Topics 6–7. For a user who has already read about Topics 1–5, Document A has zero information gain despite its length, while Document B - at half the word count - offers significant new value through Topics 6–7. Document B ranks higher for that user.
The implication is clear: one paragraph of genuinely novel insight outranks three paragraphs of redundant explanation.
Strategic Recommendations for SEOs
1. Conduct Information Gain Audits
Identify your target topic, analyze the top ten ranking pages, and map what information elements each one covers. Distinguish "consensus information" - content appearing in most or all pages - from genuine gaps that no one covers. Your content should address the consensus completely while focusing creative energy on filling those gaps.
A useful AI-assisted approach: prompt an LLM to write a comprehensive article on your topic. The output represents near-perfect consensus content. Compare it to your draft - what's in the AI version is baseline; what's only in your version is your information gain advantage.
2. Leverage Subject Matter Experts (SMEs)
SMEs possess knowledge that does not exist in any published content - which means it is automatic information gain. Show them top-ranking content and ask what's missing, what's incorrect, or what nuance is lost. Conduct interviews to extract unique anecdotes and case studies. Tap their access to proprietary data - company metrics, customer feedback, internal research - that competitors cannot access through conventional research.
Content Review
Show SMEs top-ranking content. Ask: "What's missing?" "What's incorrect?" "What nuance is lost?" Document their insights.
Interview-Based Content
Extract unique anecdotes and case studies. Example: "We tried the standard approach, but found that..." - impossible for LLMs to generate.
Data Access
SMEs often have proprietary data - company metrics, customer feedback, research results - unavailable to any competitor who relies on public sources.
3. Create Original Research and Data
Original research is definitionally unique - it cannot be replicated by competitors without conducting the same research. This provides the closest thing to a guaranteed information gain score of 1.0 for specific data points. Research types include quantitative customer surveys, qualitative interviews and case studies, competitive product tests, and annual industry benchmarking studies. As a compound benefit, original research attracts inbound links from other publishers citing your data.
4. Work Across Departments
Marketing teams alone rarely have frontline insights. Real customer problems - and real customer language - emerge in Customer Support, Sales, and Product/Engineering teams. Customer Support knows the most frequent issues, the questions customers actually ask, and the misconceptions that never get addressed in marketing content. Sales knows the objections, the decision-making factors, and what competitors are saying. Engineering knows the technical details and implementation mistakes that outsiders can only guess at.
Schedule quarterly cross-functional content meetings with a single question: "What do customers ask you that isn't well-covered online?"
5. Use AI to Identify Consensus (Not Create Content)
LLMs are trained on existing content. By definition, they can only produce consensus information - they cannot create information gain. This limitation can be turned into a strategic tool: generate an AI article on your topic to get a precise baseline of what consensus looks like, then focus your human energy entirely on what the AI could not write.
The practical test: If an LLM can write it, it's not information gain. If an LLM can't write it - because it comes from your proprietary data, unique experience, or original research - it IS information gain.
6. Structure Content for Incremental Value
Users may land on your page after already reading a competitor's article. Structure your content to acknowledge this. Briefly cover the consensus so first-time readers aren't lost, then clearly signal where your content diverges: "Most guides stop here. Here's what they don't cover..." Then dedicate the majority of the piece to your unique insights, marked visibly as new information.
7. Monitor Information Gain Competitively
Set a monthly cadence to review the top ten results for your target keywords and note any new information that wasn't there 30 days ago. When a competitor publishes new insights, don't copy them - respond to them. "We tested those five strategies. Here's what actually worked" adds information gain on top of their information gain, rather than simply echoing it.
8. Optimize for "Second Click" Scenarios
Design content explicitly for users who have already consumed the basics. "What They Don't Tell You" articles assume the reader already knows the fundamentals and focus entirely on advanced or nuanced points. Comparison content assumes the reader knows the individual options and provides the detailed comparative analysis that requires actual testing. Troubleshooting guides assume the reader has already tried the standard solutions and address the edge cases. Meta-analyses synthesize findings across multiple sources and add original interpretation.
9. Build Information Gain Dashboards
Track your unique content assets systematically: proprietary research studies, original datasets, unique case studies, SME-contributed insights per article, company-specific examples as a percentage of content, original frameworks and methodologies, and topics covered exclusively by your publication. This dashboard identifies where your content needs an information gain refresh and demonstrates the ROI of investing in SME time and original research.
Why Every SEO Professional Must Understand This Patent
1. Paradigm Shift from Relevance to Value
The old model was: Query → Relevant Content → Rankings, with the central question being "Does this answer the question?" The new model adds an additional layer: Query → Relevant Content → Information Gain Assessment → Rankings, with the question now being "Does this add value beyond existing answers?" Relevance alone is no longer sufficient - it is merely the entry requirement.
2. Algorithmic Detection of Content Quality
This patent reveals that Google has a technical method to detect "copycat" content - not just duplicate content detection, which has existed for years, but a novel capability: detecting information overlap even when content is completely reworded. The system uses semantic understanding to identify redundancy at the meaning level, not the word level. Content spinning is provably ineffective against this system. The only path forward is genuinely new information.
3. User Journey Personalization at Scale
This patent is an early blueprint for personalized SERPs based on knowledge state. A first-time searcher and a returning researcher submitting the same query may see fundamentally different results. Content must be designed to serve users at specific stages of their knowledge journey - not just targeting a keyword, but targeting where a user is in their understanding of a topic.
4. Voice and Assistant Optimization Becomes Critical
In voice and assistant contexts, information gain filtering is not a nice-to-have - it is essential. Audio content is linear; users cannot scan or skip. Hearing the same information repeated across multiple assistant responses is uniquely frustrating. The patent specifically addresses TTS scenarios, signaling that voice optimization and information gain are deeply linked. Modular, extractable content with clear information hierarchy will perform best in these contexts.
5. Defensive SEO Becomes Necessary
A new competitive risk emerges from this system. If a competitor publishes content covering everything your guide covers plus additional unique topics, users who have already read your guide will find the competitor's content has high information gain relative to their existing knowledge. Your content will appear to have zero information gain for those users - even though you published first. Continuous content enhancement and competitive monitoring become mandatory, not optional.
6. Validates Investment in Original Research
The historical question - "Is original research worth the cost?" - now has a patent-grounded answer: original research produces guaranteed information gain, which is a documented ranking signal. The business case for a $50,000 research study becomes measurable: unique content that ranks above all competitors with similar relevance, data that gets cited in AI summaries, backlinks from publishers citing your findings, and thought leadership positioning that compounds over time.
7. AI Content Arms Race Implications
AI-generated content is, by definition, high on consensus and zero on information gain. LLMs cannot include proprietary data, unique experiences, or novel research - they are trained on what already exists. Human-expert content, by contrast, includes both the consensus baseline and unique insights that no algorithm can generate. As AI makes consensus content free and abundant, information gain becomes the only scarce resource and the primary ranking differentiator.
Strategic insight: The more AI commoditizes the creation of consensus content, the more valuable human expertise and original data become. This patent describes exactly the mechanism by which Google will reward one and discount the other.
Practical Implementation Checklist
Immediate Actions
- List your top 10 ranking articles; for each, identify what's unique vs. consensus; prioritize updates for low-scoring content
- Identify subject matter experts in your organization; map their expertise to content topics; schedule initial meetings
- Review top 3 competitors' recent content; note any unique information they've published; assess if they're outpacing you on information gain
Short-Term Implementation
- Create an SME interview template; establish a cross-departmental content input process; set up an information gain tracking system
- Identify 3 topics where you can create unique value; plan an original research or data analysis project; develop "what's missing" content briefs
- Implement tracking for document consumption patterns; plan for personalization capabilities as they become available
Long-Term Strategy
- Commission or conduct your first original research project; analyze proprietary data for shareable insights; develop case studies from customer experiences
- Educate writers on information gain concept; train editors to identify and request unique insights; align the organization on information gain as a content priority
- Define information gain KPIs; track ranking improvements for enhanced content; monitor engagement metrics and competitive positioning
The SEO Takeaway
Google's Patent US20200349181A1 represents a fundamental evolution in how search engines evaluate and rank content. While traditional SEO focused on relevance (does this answer the query?), modern SEO must additionally optimize for information gain (does this add value beyond existing answers?).
- Consensus content is now table stakes - accurate coverage is the minimum requirement, not a competitive advantage
- Information gain is the new differentiator - unique insights, original research, expert perspectives will increasingly outrank consensus-only content
- User context matters - rankings may become personalized based on what users have already consumed
- E-E-A-T gets algorithmic teeth - this patent provides a technical method to reward Experience and Expertise
- AI makes this more important - as LLMs commoditize consensus content, human expertise becomes the only sustainable moat
Stop creating content by analyzing what ranks. Start creating content by identifying what's missing. The future of SEO belongs to publishers who can consistently provide information users can't get anywhere else.