
Wieloetapowy system wyszukiwania Google łączy klasyczne mechanizmy wyszukiwania informacji z generatywną AI, wykorzystując silniki utrzymujące kontekst, orkiestrację LLM i weryfikację opartą na embeddingach - przekształcając wyszukiwanie z izolowanych zapytań w kontekstowe rozmowy.
Wprowadzenie: Od izolowanych zapytań do konwersacji z pamięcią kontekstu
Wyszukiwarki tradycyjnie traktowały każde zapytanie jako niezależne, izolowane żądanie. Wpisujesz „algorytmy uczenia maszynowego", dostajesz listę dokumentów. Wpisujesz „nadzorowane vs nienadzorowane", dostajesz inną listę -odłączoną od pierwszego zapytania, pozbawioną kontekstu, zaczynającą od zera.
Ta fragmentacja tworzy obciążenie poznawcze. Użytkownicy muszą ręcznie rekonstruować kontekst, przeformułowywać zapytania i składać informacje w wielu etapach. Tymczasem modele generatywne operujące na izolowanych promptach ryzykują tworzenie halucynowanych lub nadmiernie uogólnionych podsumowań bez ugruntowania w zweryfikowanych dokumentach.
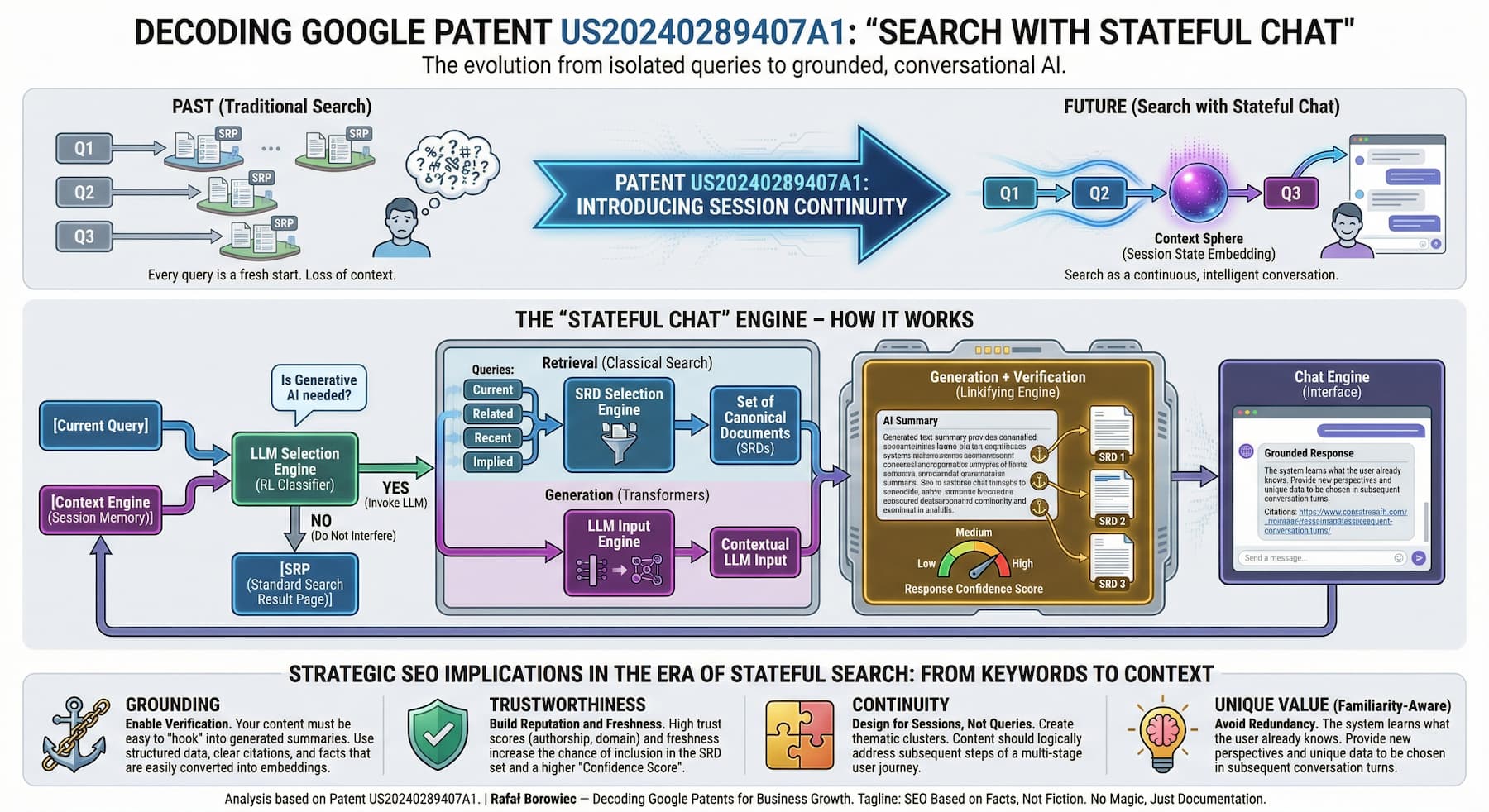
Patent US20240289407A1 adresuje to strukturalne ograniczenie wprowadzając stanowe, wieloetapowe wyszukiwanie, które łączy klasyczne pipeline'y wyszukiwania (dokumenty/strony wyników wyszukiwania) z modelami generatywnymi opartymi na transformerach pod zunifikowanym silnikiem kontekstu.
System utrzymuje trwały stan użytkownika w kolejnych etapach, generuje zapytania syntetyczne i implikowane z kontekstu sesji, adaptacyjnie wybiera które modele generatywne wywołać (lub całkowicie je pomija), i weryfikuje generowane podsumowania w języku naturalnym poprzez mechanizm linkowania weryfikacyjnego oparty na embeddingach względem bazowych dokumentów źródłowych.
Metadane patentu
- Numer patentu: US20240289407A1
- Data zgłoszenia: 27 lutego 2024
- Data publikacji: 29 sierpnia 2024
- Zgłaszający: Google LLC
- Wynalazcy: Mahsan Rofouei, Anand Shukla, Qing Wei, Chi Tang, Ryan Brown, Enrique Piqueras
- Oficjalny tytuł: Wyszukiwanie ze czatem z pamięcią kontekstu
1. Główny problem: Fragmentacja intencji i kontekstu
Tradycyjne wyszukiwarki cierpią na amnezję na poziomie sesji. Każde zapytanie istnieje w izolacji:
- Utracona ciągłość: Zapytania typu „a co z implementacjami w Pythonie?" zakładają wcześniejszy kontekst, który system już zapomniał.
- Redundantne pobieranie: Użytkownicy ręcznie doprecyzowują zapytania aby przywrócić kontekst, zmuszając system do ponownego pobierania semantycznie powiązanych dokumentów, które już wyświetlił.
- Obciążenie poznawcze: Użytkownicy muszą mentalnie śledzić wątek swoich badań, rekonstruując połączenia, które system powinien utrzymywać.
- Ryzyko halucynacji generatywnej: LLM operujące na izolowanych promptach tworzą podsumowania bez zakotwiczenia w zweryfikowanych, wiarygodnych dokumentach.
Użytkownik badający „architekturę transformerów" może następnie zapytać „mechanizmy uwagi", a potem „różnice względem RNN". Tradycyjny system traktuje każde z nich jako niezależne zdarzenie. Stanowe wyszukiwanie rozpoznaje je jako ciągłą konwersacyjną podróż i utrzymuje trwały kontekst sesji.
2. Architektura rozwiązania: Stanowe wyszukiwanie z LLM
Komponenty systemowe
1. Silnik kontekstu (Context Engine)
Trwała warstwa stanowa utrzymująca reprezentację sesji użytkownika poprzez:
- Embedding reprezentujący kontekst użytkownika: Kodowanie historii zapytań, wybranych dokumentów wyników wyszukiwania (SRD), i sygnałów zaangażowania w znormalizowaną reprezentację wektorową
- Generowanie zapytań implikowanych: Wywnioskowanie ukrytych intencji z wzorców interakcji sesji
- Pamięć sesji: Śledzenie poprzednich zapytań, wyświetlonych SRD, i zachowania użytkownika w danej sesji
2. Orkiestrator LLM (LLM Orchestrator)
Klasyfikator decydujący czy i kiedy wywołać modele generatywne:
- Klasyfikacja intencji: Określanie czy zapytanie wymaga podsumowania generatywnego vs klasycznego listingu
- Wybór modelu: Routing do odpowiedniego LLM na podstawie złożoności zapytania (duże, średnie, małe modele)
- Warunki pominięcia: Całkowite unikanie generowania dla prostych zapytań nawigacyjnych lub transakcyjnych
3. Silnik weryfikacji odpowiedzi (Response Linkifying Engine)
Weryfikuje wygenerowane podsumowania względem bazowych SRD:
- Porównanie embeddingów: Oblicza odległość między fragmentami wygenerowanego tekstu a embeddingami dokumentów
- Progowanie linków: Gdy odległość embedding < próg, fragment jest linkowany do weryfikującego SRD
- Adnotacja pewności: Każdy link otrzymuje wskaźnik pewności bazując na bliskości semantycznej
Przepływ metody
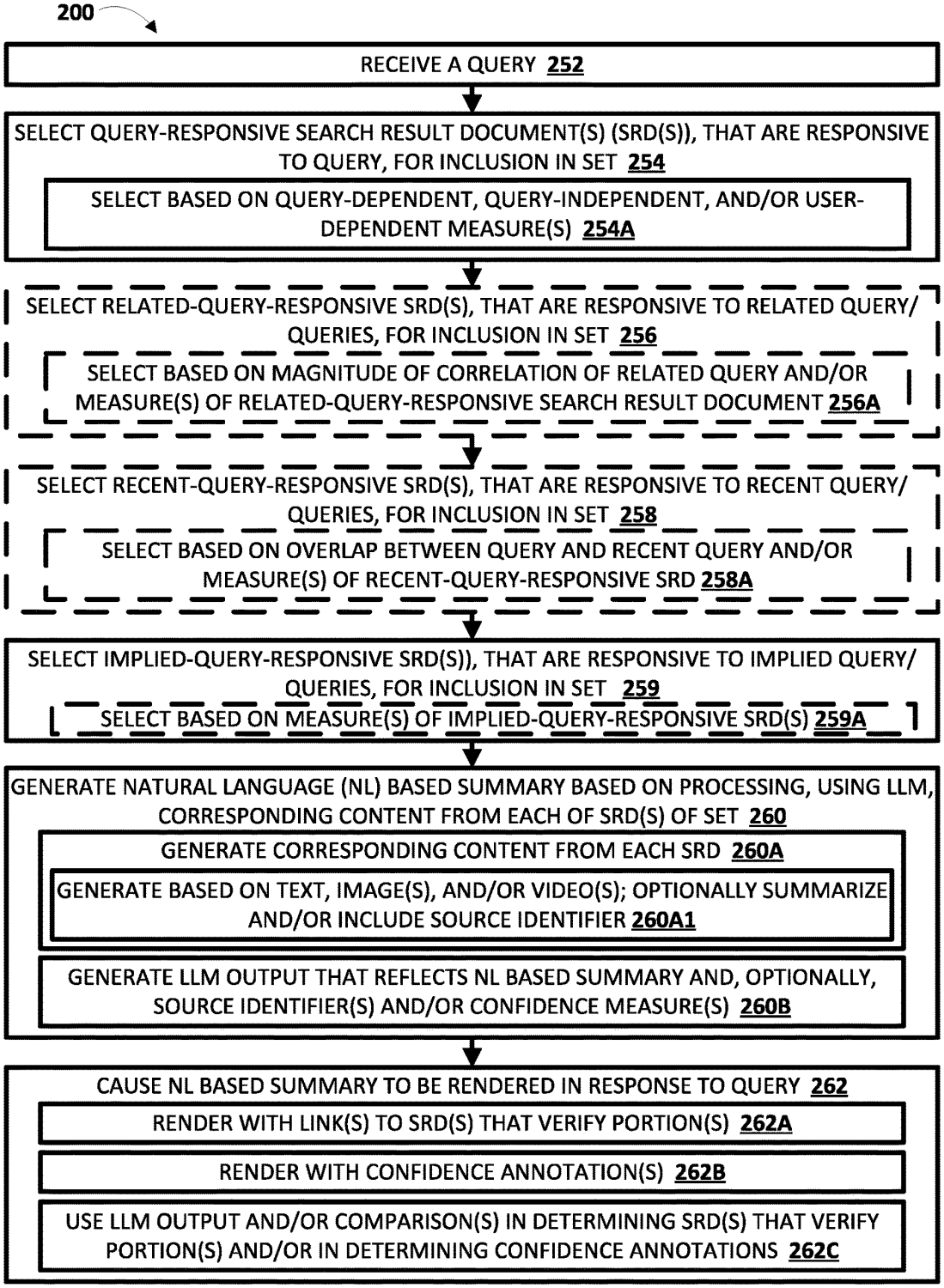
Patent definiuje szczegółowy, wieloetapowy pipeline (Metoda 200):
- Otrzymanie zapytania (252): Przechwycenie zapytania użytkownika wraz z identyfikatorem sesji
- Wybór SRD responsywnych na zapytanie (254): Klasyczne pobieranie bazujące na bieżącym zapytaniu
- Wybór SRD responsywnych na powiązane zapytanie (256): Pobieranie dokumentów pasujących do zapytań semantycznie bliskich bieżącemu
- Wybór SRD responsywnych na ostatnie zapytanie (258): Włączanie dokumentów z poprzednich zapytań w sesji
- Wybór SRD responsywnych na zapytanie implikowane (259): Dodawanie dokumentów odpowiadających na ukryte intencje wywnioskowane przez silnik kontekstu
- Generowanie podsumowania w języku naturalnym (260): LLM syntetyzuje odpowiedź używając połączonego zestawu SRD jako kontekstu
- Renderowanie podsumowania NL w odpowiedzi na zapytanie (262): Wyświetlenie wygenerowanej treści użytkownikowi z linkami weryfikacyjnymi
3. Mechanizmy techniczne: Embeddingi, weryfikacja, pewność
Pipeline weryfikacji oparty na embeddingach
Kluczowy mechanizm zapobiegania halucynacjom w Metodzie 400:
- Podział wygenerowanego tekstu: Podziel odpowiedź LLM na atomowe jednostki semantyczne (zdania, klauzule, frazy)
- Oblicz embeddingi fragmentów: Każda jednostka jest kodowana do znormalizowanego wektora embeddingowego
- Porównaj z embeddingami SRD: Oblicz odległość cosinusową między każdym fragmentem a zbiorem embeddingów SRD
- Zastosuj próg linkowania: Jeśli odległość < próg_linkyfikacji, fragment jest linkowany do najbliższego SRD
- Adnotuj pewność: Każdy link otrzymuje wskaźnik pewności ∈ [0,1] bazując na bliskości embeddingu
Przykład:
Wygenerowane zdanie: „Architektury transformerów używają mechanizmów self-attention zamiast rekurencji."
- Fragment 1: „Architektury transformerów używają mechanizmów self-attention" → linkowany do SRD:
arxiv.org/abs/1706.03762(wskaźnik pewności: 0.92) - Fragment 2: „zamiast rekurencji" → linkowany do SRD:
stanford.edu/~rnn-comparison(wskaźnik pewności: 0.78)
Użytkownik widzi podsumowanie w języku naturalnym z podkreślonymi, klikalnym linkami do zweryfikowanych źródeł.
Świadomość znajomości (Familiarity Awareness)
Metoda 600 adaptuje generowanie na podstawie wcześniejszej ekspozycji użytkownika:
- Śledzenie ekspozycji: System rejestruje które SRD użytkownik już zobaczył w sesji
- Modulacja szczegółów: Dokumenty wcześniej wyświetlane są podsumowywane bardziej zwięźle lub całkowicie pomijane
- Adaptacja świeżości: Priorytetyzowanie nowych informacji, które nie zostały jeszcze przedstawione
Przykład:
Etap 1: Zapytanie „budżet NLP"
→ System wyświetla podsumowanie SRD: huggingface.co/tokenization-guide
Etap 2: Zapytanie „podtokenizacja WordPiece"
→ System wykrywa że huggingface.co/tokenization-guide był już wyświetlony
→ Generuje bardziej zwięzłe odniesienie: „Jak wspomniano wcześniej, WordPiece jest wariantem BPE..."
→ Priorytetyzuje nowy materiał z dodatkowych SRD
4. Typy wyboru SRD: Zapytanie, powiązane, ostatnie, implikowane
1. Responsywne na zapytanie (Query-Responsive)
Klasyczne pobieranie oparte na bieżącym zapytaniu.
2. Responsywne na powiązane zapytanie (Related-Query-Responsive)
Pobieranie dokumentów powiązanych z zapytaniami semantycznie bliskimido bieżącego:
- Ekspansja syntetyczna: Generowanie kandydujących zapytań poprzez przestrzeń embeddingową
- Klasteryzacja podobieństwa: Grupowanie zapytań w rodziny intencji
- Pobieranie międzyzapytaniowe: Włączanie SRD z klastra intencji użytkownika
3. Responsywne na ostatnie zapytanie (Recent-Query-Responsive)
Włączanie SRD z poprzednich zapytań w bieżącej sesji:
- Ciągłość sesji: Utrzymywanie kontekstu w sekwencji zapytań
- Dekrecja temporalna: Dokumenty z ostatnich zapytań otrzymują wyższą wagę
4. Responsywne na zapytanie implikowane (Implied-Query-Responsive)
Najbardziej zaawansowany tryb -wywnioskowanie ukrytych intencji:
- Predykcja intencji: LLM wywnioskuje co użytkownik może chcieć zapytać w następnym kroku
- Proaktywne pobieranie: Pre-fetch dokumentów dla implikowanych zapytań
- Oczekująca dostawa: Przygotowywanie odpowiedzi przed jawnym pytaniem użytkownika
Przykład:
Jawne zapytanie: „Fine-tuning BERT"
Implikowane zapytania wygenerowane przez system:
- „wymagania obliczeniowe fine-tuningu BERT"
- „zbiory danych do fine-tuningu BERT"
- „BERT vs RoBERTa wydajność"
System pobiera SRD dla tych implikowanych zapytań proaktywnie, tak że gdy użytkownik naturalnie pyta „wymagania obliczeniowe?", odpowiedź jest już przygotowana.
5. Adnotacja pewności i wskaźniki gęstości weryfikacji
Wynik pewności na poziomie linku
Każdy link weryfikacyjny otrzymuje wskaźnik pewności bazując na:
- Bliskość embedding: Odległość cosinusowa między fragmentem a SRD
- Wiarygodność dokumentu: Wynik zaufania SRD (autorstwo, świeżość, domena)
- Świeżość temporalna: Jak ostatnio dokument był zaktualizowany
Formuła:
wynik_pewności = α·(1 - odległość_embedding) + β·wiarygodność_dokumentu + γ·świeżość
gdzie α, β, γ to wagi hiperparametrów.
Wskaźnik gęstości weryfikacji
Gęstość weryfikacji = (liczba zweryfikowanych fragmentów) / (całkowita liczba fragmentów)
Wysoka gęstość (np. >0.8) sygnalizuje silnie ugruntowane podsumowanie. Niska gęstość (<0.4) wskazuje ryzyko halucynacji -system może wyświetlić ostrzeżenie lub wrócić do klasycznego listingu.
Przykład progowania:
- Gęstość > 0.75: Wyświetl podsumowanie NL z wysoką pewnością
- 0.4 < Gęstość ≤ 0.75: Wyświetl podsumowanie + klasyczny listing
- Gęstość ≤ 0.4: Pomiń generowanie, pokaż tylko klasyczne wyniki
6. Implikacje dla SEO: Od słów kluczowych do autorytetu kontekstowego
Strategiczne przesunięcie
Patent US20240289407A1 przesuwa ramy SEO z optymalizacji izolowanych zapytań do autorytetu kontekstowego w wieloetapowych podróżach użytkownika.
Co zmienić
- Priorytetyzuj wiarygodność dokumentu: Autorstwo, dane strukturalne, cytowania i sygnały E-E-A-T stają się krytyczne dla progów zaufania.
- Projektuj treści z myślą o całej ścieżce użytkownika: Treść powinna wspierać wieloetapowe podróże, nie tylko izolowane zapytania.
- Wsparcie linkowania weryfikacyjnego: Używaj jasnego, semantycznie odrębnego języka który tworzy wyraźne reprezentacje embeddingowe w wyraźne klastry.
- Świeżość temporalna: Regularne aktualizacje z wyraźnymi znacznikami czasowymi poprawiają rankingi świeżości.
- Odrębność semantyczna: Unikaj redundantnych treści na podobne zapytania -każdy dokument powinien zajmować unikalny region semantyczny.
Co robić
- Używaj danych strukturalnych: Schema.org markup (Article, TechArticle, FAQPage) wspiera mechanizmy zaufania.
- Jawne cytowania i źródła: Linkuj do autorytatywnych źródeł zewnętrznych -system nagradza „weryfikowalność".
- Segmentacja treści: Rozbij artykuły na atomowe, semantycznie samowystarczalne sekcje na potrzeby podziału embeddingów.
- Linkowanie wewnętrzne międzyzapytaniowe: Twórz sieci treści dla powiązanych tematów -wspiera selekcję SRD responsywnych na powiązane zapytanie.
- Używaj spójnego semantycznego frazowania: Stabilny, dobrze ustrukturyzowany język poprawia stabilność dopasowania embeddingu między etapami; unikaj niejasnego lub nadmiernie kolokwialnego frazowania.
Czego unikać
- Pokrywających się redundantnych treści: Powtórzenia między dokumentami mogą być depriorytetyzowane w pipeline'ach świadomych znajomości.
- Nieprzejrzystego autorstwa lub niezweryfikowanych twierdzeń: Niska wiarygodność redukuje wagę pewności i prawdopodobieństwo włączenia SRD.
- Tekstu wypełnionego słowami kluczowymi lub płytkiego: Słaba spójność semantyczna może pogorszyć bliskość embeddingu, nie spełniając progów linkifikacji.
- Izolowanej, jedno-zapytaniowej optymalizacji: Treść optymalizowana tylko pod izolowane słowa kluczowe będzie słabo działać w kontekstach wyszukiwania z pamięcią kontekstu na poziomie sesji.
7. Praktyczne przykłady implementacji
Przykład 1: Klasteryzacja kontekstowa dokumentów
Zaimplementuj architekturę wielostronicową gdzie każdy dokument adresuje odrębne podzapytanie szerszego tematu. Polinkuj je używając opisowego tekstu kotwicy.
Dlaczego: Wspiera wybór SRD dla pobierania responsywnego na powiązane i ostatnie zapytania. Silnik kontekstu może wyświetlać semantycznie sąsiednie dokumenty w etapach.
Przykład 2: Markup gotowy do ugruntowania
Osadzaj strukturalne cytowania używając Schema.org:
<script type="application/ld+json">
{
"@type": "Article",
"citation": [
{
"@type": "CreativeWork",
"url": "https://patents.google.com/patent/US20240289407A1",
"name": "US20240289407A1 - Wyszukiwanie ze czatem z pamięcią kontekstu"
}
],
"author": {
"@type": "Person",
"name": "Rafał Borowiec"
},
"dateModified": "2026-02-16"
}
</script>Dlaczego: Ułatwia weryfikację i scoring pewności poprzez strukturalne dane autorstwa i cytowania.
Przykład 3: Aktualizacje świadome znajomości
Aktualizując treści evergreen, podkreślaj nowe dane lub perspektywy zamiast restytutować wcześniejsze informacje.
Używaj wizualnych calloutów lub etykiet „Zaktualizowano:" aby sygnalizować świeżą treść.
Dlaczego: Dopasowuje się do pipeline'u podsumowania świadomego znajomości (Metoda 600 w patencie) -system moduluje szczegół na podstawie wcześniejszej ekspozycji użytkownika.
Przykład 4: Doprecyzowanie napędzane interakcją
Monitoruj czas przebywania i metryki zaangażowania aby zidentyfikować które sekcje utrzymują uwagę użytkownika; dopracuj te sekcje aby poprawić istotność dla przyszłej selekcji SRD.
Dlaczego: Klasyfikatory są trenowane na sygnałach zaangażowania -trwała interakcja sygnalizuje pozytywną istotność.
8. Podsumowanie: Wyszukiwanie jako ekosystem generatywny z pamięcią kontekstu
Patent US20240289407A1 definiuje strukturalne przesunięcie od pobierania izolowanego zapytaniami do orkiestracji wyszukiwania z utrzymywaniem kontekstu wyszukiwania. Łączy pobieranie, klasyfikację i podsumowanie generatywne pod zunifikowanym frameworkiem embeddingów i weryfikacji.
Architektonicznie, mostkuje tradycyjne indeksy wyszukiwania z wnioskowanie generatywnym opartym na transformerach, podkreślając:
- Ugruntowanie: Linkifikacja oparta na embeddingach zakotwicza generowaną treść do kanonicznych dokumentów
- Adnotacja pewności: Przejrzystość poprzez gęstość weryfikacji i metryki wiarygodności
- Trwałość stanu użytkownika: Ciągłość na poziomie sesji zastępuje izolację zapytań
- Adaptacyjna orkiestracja: Warunkowy wybór modelu bazujący na klasyfikatorach trenowanych przez uczenie ze wzmocnieniem
Kluczowy wniosek dla strategów SEO
Wyszukiwanie zmienia się w wieloetapowy ekosystem generatywny.
Liczy się już nie pojedyncze zapytanie, ale cała podróż użytkownika przez kilka powiązanych pytań. Twoja treść musi być:
- Weryfikowalna - z konkretnymi źródłami i danymi strukturalnymi
- Wiarygodna - z wyraźnym autorstwem i sygnałami E-E-A-T
- Kontekstowo odrębna - każdy dokument zajmuje unikalną przestrzeń semantyczną
System ocenia teraz niezawodność dokumentu, bliskość embeddingu i adaptowalność kontekstową - nie gęstość słów kluczowych ani sam PageRank.
Model rankingowy oparty wyłącznie na słowach kluczowych traci znaczenie.
Zaczyna się era autorytetu kontekstowego.
Podsumowanie
Patent US20240289407A1 wprowadza stanowy, wieloetapowy framework wyszukiwania, który łączy klasyczne pipeline'y wyszukiwania z modelami generatywnymi opartymi na transformerach, utrzymując trwały kontekst użytkownika w sesjach wyszukiwania poprzez reprezentację stanu opartą na embeddingach.
Kluczowa innowacja systemu leży w warunkowej orkiestracji i weryfikacji opartej na embeddingach - modele generatywne są wywoływane adaptacyjnie na podstawie klasyfikatorów trenowanych ze wzmocnieniem, a ich wyniki są ugruntowywane poprzez dopasowanie bliskości semantycznej z kanonicznymi dokumentami źródłowymi.
Dla strategów SEO, wskazuje to na strukturalne przesunięcie: sukces zależy od weryfikowalnej, wiarygodnej, kontekstowo odrębnej treści, która utrzymuje semantyczne dopasowanie w wieloetapowych podróżach użytkownika, nie izolowaną optymalizację słów kluczowych lub tradycyjny PageRank sam w sobie.