
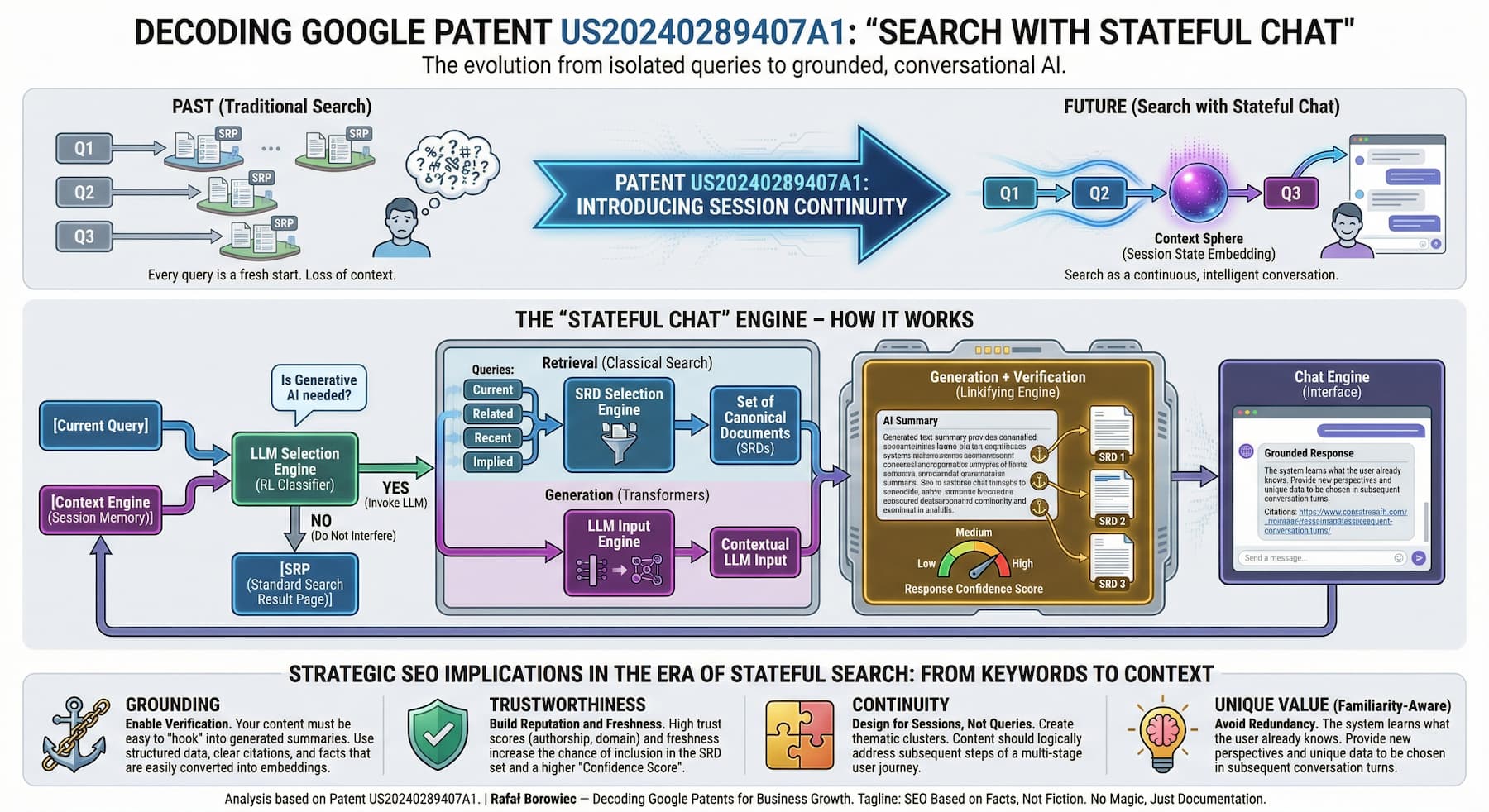
Google's stateful multi-turn search framework merges classical retrieval with generative AI through context engines, LLM orchestration, and embedding-based verification -transforming search from isolated queries into contextual conversations.
Introduction: From Static Queries to Stateful Conversations
Search engines have traditionally treated each query as an independent, isolated request. Type "machine learning algorithms," get a list of documents. Type "supervised vs unsupervised," get another list -disconnected from your first query, stripped of context, starting from zero.
This fragmentation creates cognitive overhead. Users must manually reconstruct context, reformulate queries, and piece together information across multiple turns. Meanwhile, generative models operating on isolated prompts risk producing hallucinated or over-generalized summaries without grounding in verified documents.
Patent US20240289407A1 addresses this structural limitation by introducing a stateful, multi-turn search framework that merges classical retrieval pipelines (search result documents/pages) with transformer-based generative models under a unified context engine.
The system maintains persistent user state across turns, generates synthetic and implied queries from session context, adaptively selects which generative models to invoke (or bypass them entirely), and verifies generated natural-language summaries through embedding-based linkification against underlying source documents.
Patent Metadata
- Patent number: US20240289407A1
- Filing date: February 27, 2024
- Publication date: August 29, 2024
- Applicant: Google LLC
- Inventors: Mahsan Rofouei, Anand Shukla, Qing Wei, Chi Tang, Ryan Brown, Enrique Piqueras
- Official title: Search with stateful chat
1. Core Problem: Fragmentation of Intent and Context
Traditional search engines suffer from session-level amnesia. Each query exists in isolation:
- Lost continuity: Queries like "what about Python implementations?" assume prior context that the system has already forgotten.
- Redundant retrieval: Users manually refine queries to re-establish context, forcing the system to re-fetch semantically related documents it already surfaced.
- Cognitive overload: Users must mentally track the thread of their research, reconstructing connections the system should maintain.
- Generative hallucination risk: LLMs operating on isolated prompts produce summaries without anchoring to verified, trustworthy documents.
The patent's objective is to create a stateful search ecosystem where:
- User state persists across turns (queries, documents viewed, actions taken, device signals)
- Generative models are invoked conditionally, only when beneficial
- Generated content is verified through semantic embedding comparison with source documents
- Confidence levels reflect document trustworthiness and verification density
2. System Architecture: Key Patent Elements
2.1 Context Engine (113)
Role: Maintains and updates user state (871) across turns.
Mechanism: Aggregates prior queries, search result documents (SRDs), search result pages (SRPs), user actions (clicks, dwell time), and device signals into embeddings representing session context.
Connection to Transformers: Uses LLMs for synthetic query generation and context summarization.
Impact: Introduces session-level statefulness -each new query is interpreted relative to prior turns, not in isolation.
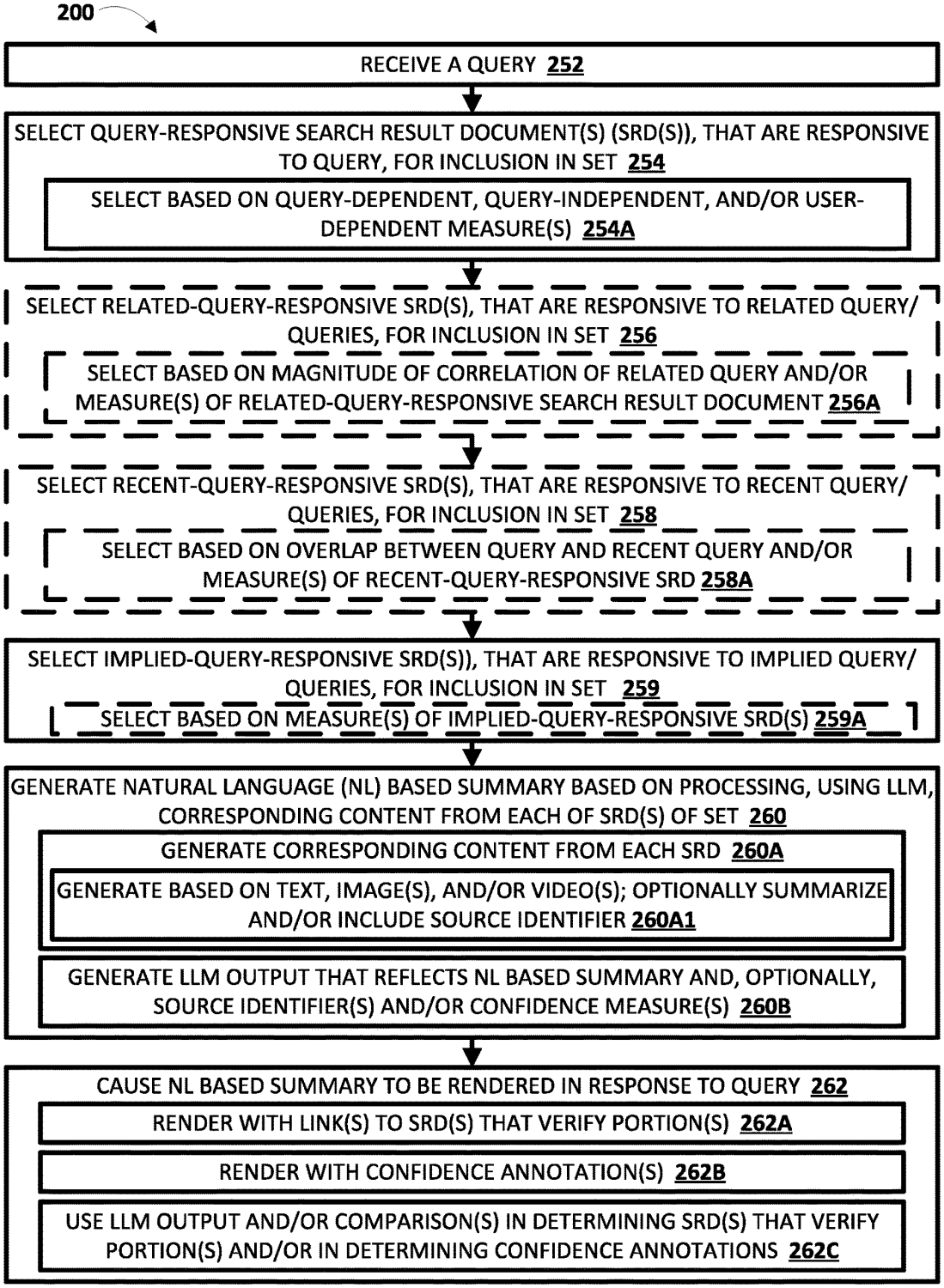
2.2 SRD Selection Engine (122)
Role: Selects responsive search result documents (SRDs) from multiple sources beyond the current query:
- Current query-responsive documents
- Related query-responsive documents
- Recent query-responsive documents from session history
- Implied query-responsive documents (synthetic queries generated by context engine)
Mechanism: Uses query-dependent measures (relevance scoring), query-independent measures (PageRank, freshness), and user-dependent measures (trustworthiness, authorship verification).
Impact: Expands retrieval scope beyond the immediate query, creating a merged canonical document set for grounding generative output.
2.3 LLM Selection Engine (132)
Role: Classifies query + state to decide which generative model(s) to invoke -or none ("do not interfere").
Mechanism: Uses classifiers trained with reinforcement learning on engagement metrics (sustained interaction vs. abrupt direction change).
Impact: Introduces adaptive orchestration -the system can dynamically choose between retrieval-only (traditional SRP) or generative response (LLM-generated summary).
2.4 LLM Input Engine (134)
Role: Tokenizes and embeds user state and SRD content for transformer input.
Mechanism: Constructs contextualized embeddings incorporating:
- User familiarity signals (which topics the user has already explored)
- Permissions (personal content if allowed)
- Session history embeddings
Impact: Enables token-level personalization within LLM inference, allowing the model to modulate summary detail based on user familiarity.
2.5 Response Linkifying Engine (138)
Role: Verifies generated natural-language content by comparing embeddings of generated text portions with document embeddings.
Mechanism: Embedding distance threshold determines whether a text portion can be linked to a verifying SRD.
Impact: Provides factual grounding and traceability for generative output -generated claims are anchored to canonical source documents, reducing hallucination risk.
2.6 Response Confidence Engine (140)
Role: Assigns confidence levels (high/medium/low) to generated portions based on:
- Verification density (how many generated portions are successfully linkified)
- SRD trustworthiness (authorship, domain reputation, freshness)
Impact: Introduces transparency layer for generative summaries -users and ranking systems can assess reliability.
2.7 Chat Engine (144)
Role: Manages interactive, stateful natural-language dialog; updates user state after each turn; integrates multimodal outputs (text, images, video).
Impact: Converts search into continuous, context-aware conversation with retrieval grounding -search becomes a persistent knowledge session, not a series of disconnected lookups.
2.8 Reinforcement-Trained Classifiers (152)
Role: Classify query/state into categories guiding downstream model selection:
- Creative text generation
- Summarization
- Clarification requests
- Next-step suggestions
- "Do not interfere" (bypass generative models, return traditional SRP)
Mechanism: Rewarded by sustained engagement; penalized by abrupt direction change.
Impact: Enables adaptive model routing tuned to user satisfaction signals -generative models are invoked only when they enhance the experience.
2.9 Embedding Encoders (158)
Role: Generate embeddings for verification and confidence scoring.
Impact: Provide the geometric substrate for grounding generative content to canonical documents -semantic proximity becomes a proxy for factual alignment.
3. Training vs Inference: Distinct Phases
Training Phase
- Classifiers (152): Trained using reinforcement learning from user engagement data (sustained interaction = positive reward; abrupt direction change = negative reward).
- Context Engine LLMs: Trained on search logs to predict synthetic queries based on session history.
- Downstream LLMs (872A–F): Fine-tuned for discrete purposes -creative text, media generation, summarization, clarification, next-step suggestion.
- Embedding encoders: Trained separately on document corpora for semantic alignment (e.g., BERT, sentence transformers).
- Familiarity-aware LLMs: Trained to modulate summaries based on known vs. new content signals.
Inference Phase
- Context Engine: Retrieves and updates state embeddings per turn.
- Classifier: Determines whether to invoke generative models or bypass them.
- LLM Input Engine: Assembles contextual tokens (user state + SRD content).
- Generative model: Produces natural-language summary.
- Linkifying Engine: Verifies generated portions against SRD embeddings.
- Confidence Engine: Annotates verification density and trustworthiness.
- User interactions: Feed back into state for next turn.
- "Do not interfere" classification: Bypasses LLMs, returns pure search result page (SRP).
Why This Distinction Matters
Training defines the behavior of classifiers and fine-tuned LLMs. Inference executes conditional pipelines. The patent's novelty lies not in model architecture but in conditional orchestration -when and how models are applied, how context is maintained, and how generated output is verified.
4. Key Concepts Explained: SRD, SRP, Linkification, Confidence
SRD (Search Result Document)
Search Result Document -an individual document returned in search results. This is a specific page, article, or resource that the system has determined to be relevant to the user's query. SRDs serve as the fundamental units of content that can be used to generate responses or summaries.
SRP (Search Result Page)
Search Result Page -the traditional search results page presenting a list of matched documents (SRDs) along with their titles, snippets, and links. This is the classic interface we recognize from traditional search engines.
Key Distinction in Patent Context
The patent describes a system that combines both approaches:
- SRDs: Specific documents serve as a source of verification and grounding for content generated by LLMs.
- SRPs: Can be displayed as a traditional results list, particularly when the classifier decides "do not interfere" (bypass generative models).
The system selects responsive SRDs from multiple sources: current query, related queries, recent queries, and implied queries -creating a "merged canonical document set" to feed generative summaries.
Linkification (Response Linkifying Engine 138)
Process of verifying generated text portions by comparing their embeddings with document embeddings:
- Generated text is segmented into portions (sentences or clauses)
- Each portion's embedding is compared to SRD embeddings
- If embedding distance < threshold → portion is "linkified" (linked to verifying document)
- Linkified portions receive source attribution
Impact: Reduces hallucination, provides traceability, and anchors generative output to trustworthy canonical sources.
Confidence Scoring (Response Confidence Engine 140)
Confidence levels assigned to generated content based on:
- Verification density: Percentage of generated portions successfully linkified
- SRD trustworthiness: Authorship verification, domain authority, freshness, citation count
- Embedding proximity: How closely generated text aligns with source documents
Confidence levels:
- High: >80% verification, high-trust SRDs
- Medium: 50–80% verification, mixed-trust SRDs
- Low: <50% verification, weak embedding alignment
5. SEO Implications: From Keywords to Contextual Authority
5.1 Document-Level Implications
Trustworthiness and freshness explicitly influence SRD selection and confidence scoring.
- Documents with verifiable authorship, recent updates, and consistent factual grounding are more likely to be included in SRD sets that feed generative summaries.
- Linkification mechanism favors documents whose content semantically aligns with generated summaries -embedding proximity becomes a proxy for factual verification.
5.2 Session-Level Implications
Persistent user state means content relevance is evaluated in session context, not per query.
- Documents that consistently satisfy related intents across turns may gain repeated inclusion in SRD sets.
- Familiarity-aware summarization implies diminishing emphasis on repetitive information -novel, complementary documents may surface preferentially.
5.3 Token-Level Implications
Embedding-based verification operates on token embeddings.
- Precise, semantically rich phrasing improves the likelihood of verification and link inclusion.
- Ambiguous or vague language may fail embedding proximity thresholds, reducing confidence scores.
5.4 Structural Direction
Search is evolving from static ranking toward contextual orchestration, where retrieval, summarization, and user familiarity interact dynamically.
SEO efforts must align with document verifiability and contextual continuity rather than isolated keyword optimization.
6. Strategic SEO Recommendations
What to Do
- Maintain verifiable grounding: Ensure factual claims are supported by structured data (Schema.org), citations, and clear source identifiers to facilitate embedding-based verification.
- Optimize for freshness and trustworthiness: Update documents regularly; maintain author/domain reputation signals; display authorship credentials prominently.
- Design for session continuity: Create content clusters that logically extend across related queries; interlink them semantically and contextually (not just keyword-based internal linking).
- Provide distinct value for recurring topics: Familiarity-aware summarization reduces redundancy -offer new perspectives, updated data, or deeper analysis for recurring subjects.
- Use consistent semantic phrasing: Stable, well-structured language improves embedding match stability across turns; avoid ambiguous or overly colloquial phrasing.
What to Avoid
- Overlapping redundant content: Repetition across documents may be deprioritized in familiarity-aware pipelines.
- Opaque authorship or unverifiable claims: Low trustworthiness reduces confidence weighting and SRD inclusion probability.
- Keyword-stuffed or shallow text: Weak semantic coherence may degrade embedding proximity, failing linkification thresholds.
- Isolated, single-query optimization: Content optimized only for isolated keywords will underperform in session-level, stateful search contexts.
7. Practical Implementation Examples
Example 1: Contextual Document Clustering
Implement a multi-page architecture where each document addresses a distinct sub-query of a broader topic. Interlink them using descriptive anchor text.
Why: This supports SRD selection for related-query-responsive and recent-query-responsive retrieval. The context engine can surface semantically adjacent documents across turns.
Example 2: Grounding-Ready Markup
Embed structured citations using Schema.org:
<script type="application/ld+json">
{
"@type": "Article",
"citation": [
{
"@type": "CreativeWork",
"url": "https://patents.google.com/patent/US20240289407A1",
"name": "US20240289407A1 - Search with stateful chat"
}
],
"author": {
"@type": "Person",
"name": "Rafał Borowiec"
},
"dateModified": "2026-02-16"
}
</script>Why: Facilitates verification and confidence scoring through structured authorship and citation data.
Example 3: Familiarity-Aware Updates
When updating evergreen content, highlight new data or perspectives rather than restating prior information.
Use visual callouts or "Updated:" labels to signal fresh content.
Why: Aligns with the familiarity-aware summarization pipeline (Method 600 in patent) -the system modulates detail based on user's prior exposure.
Example 4: Interaction-Driven Refinement
Monitor dwell time and engagement metrics to identify which sections maintain user focus; refine those sections to improve relevance for future SRD selection.
Why: Classifiers are trained on engagement signals -sustained interaction signals positive relevance.
8. Conclusion: Search as Stateful Generative Ecosystem
Patent US20240289407A1 defines a structural shift from query-isolated retrieval toward stateful, context-aware search orchestration. It merges retrieval, classification, and generative summarization under a unified embedding and verification framework.
Architecturally, it bridges traditional search indices with transformer-based generative inference, emphasizing:
- Grounding: Embedding-based linkification anchors generated content to canonical documents
- Confidence annotation: Transparency through verification density and trustworthiness metrics
- User-state persistence: Session-level continuity replaces query isolation
- Adaptive orchestration: Conditional model selection based on reinforcement-trained classifiers
Directional Takeaway for SEO Strategists
Search is evolving into a multi-turn generative ecosystem.
What matters now isn't a single query - it's the entire user journey across multiple related questions. Your content must be:
- Verifiable - with concrete sources and structured data
- Trustworthy - with clear authorship and E-E-A-T signals
- Contextually distinct - each document occupies unique semantic space
The system now evaluates document reliability, embedding proximity, and contextual adaptability - not keyword density or PageRank alone.
The ranking game is over.
The contextual authority game has begun.
Summary
Patent US20240289407A1 introduces a stateful, multi-turn search framework that merges classical retrieval pipelines with transformer-based generative models, maintaining persistent user context across search sessions through embedding-based state representation.
The system's core innovation lies in conditional orchestration and embedding-based verification - generative models are invoked adaptively based on reinforcement-trained classifiers, and their outputs are grounded through semantic proximity matching with canonical source documents.
For SEO strategists, this indicates a structural shift: success depends on verifiable, trustworthy, contextually distinct content that maintains semantic alignment across multi-turn user journeys, not isolated keyword optimization or traditional PageRank alone.