
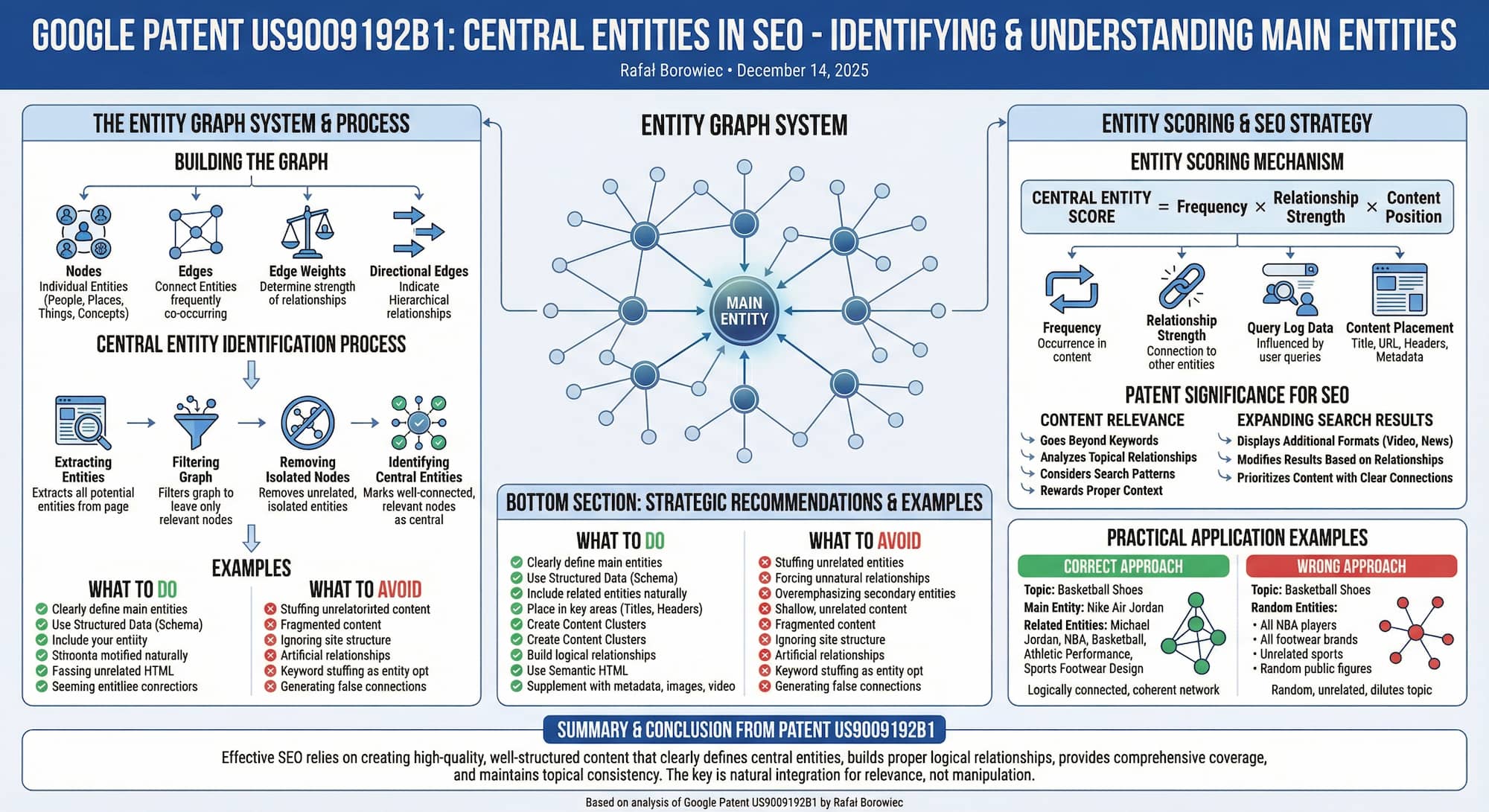
Google's patent "Identifying Central Entities" (US9009192B1), granted on April 14, 2015, describes Google's methodology for identifying and understanding the main entities (people, places, things, or concepts) appearing on web pages and the relationships between them.
Key takeaways from this article
- Google builds an entity graph where nodes are entities and edges are their relationships
- The system identifies central entities and rejects peripheral (unrelated) entities
- Entity placement in content (title, URL, headers) affects its scoring
- Clearly defining main entities and building logical relationships is key to SEO success
- Google goes beyond keyword matching - it analyzes topical relationships
What does patent US9009192B1 cover?
At its core, the patent describes a Google system that enables:
- identification of the main topics (entities) of a web page
- understanding relationships between different entities
- determining which entities are central and which are peripheral to the page content
- using this knowledge to deliver more relevant search results and additional content types
Entity definition
An entity is a person, place, thing, or concept that can be uniquely identified. Google builds a massive entity graph (Knowledge Graph) that connects billions of entities and their mutual relationships.
Key elements of the patent
Building the entity graph
The system creates an entity graph where:
Nodes
Represent individual entities (people, places, concepts, things)
Edges
Connect entities that frequently co-occur in the same resources
Edge weights
Determine the strength of relationships between entities
Directional edges
Indicate hierarchical relationships between entities
Central entity identification process
Google's system goes through the following steps:
-
Extracting potential entities
The system analyzes the web page and extracts all potential entities from the content -
Filtering the entity graph
The main entity graph is filtered, leaving only relevant nodes related to the page topic -
Removing isolated nodes
Entities unrelated to others are removed as irrelevant to the context -
Identifying central entities
The remaining, well-connected nodes are marked as the page's central entities
Entity scoring mechanism
When evaluating entities, the system considers:
- Frequency of occurrence of the entity in the content
- Strength of relationships between entities
- Query log data from users
- Entity placement in content (title, URL, metadata, headers)
Patent significance for SEO
Content relevance
The patent shows that Google:
Goes beyond keywords
Google analyzes deeper topical relationships, not just phrase matching
Analyzes entity relationships
The system examines how entities on a page are topically related
Considers search patterns
User query data influences entity evaluation
Rewards proper context
Content that properly embeds entities in context is rewarded
Expanding search results
Based on entity understanding, Google can:
- display additional content formats (video, news, images)
- modify search results based on relationships between entities
- prioritize content that clearly and correctly builds entity relationships
Strategic SEO recommendations
What to do
Entity optimization
- Clearly define main entities in your content
- Use appropriate structured data (Schema)
- Include related entities naturally and contextually
- Place entities in key areas (titles, headers, URLs)
Content structure
- Create content clusters around main entities
- Build logical relationships between entities
- Use semantic HTML
- Supplement content with relevant entity metadata
Content expansion
- Add supplementary content (images, video) related to main entities
- Create comprehensive resource pages about main entities
- Develop detailed content about related entities
What to avoid
Weak entity context
- Don't stuff random entities unrelated to the topic
- Don't force unnatural relationships between entities
- Don't overemphasize secondary entities
Poor content structure
- Don't create shallow content about many unrelated entities
- Avoid fragmented content without a clear central entity
- Don't ignore entity relationships in site structure
Manipulation attempts
- Don't create artificial entity relationships
- Avoid keyword stuffing disguised as entity optimization
- Don't generate false connections between entities
Practical application examples
Correct approach
Topic: Basketball Shoes
Main Entity: Nike Air Jordan
Related Entities:
- Michael Jordan (person)
- NBA (organization)
- basketball (sport)
- athletic performance (concept)
- sports footwear design (concept)
Why it works: All entities are logically connected to the main topic and form a coherent relationship network.
Wrong approach
Topic: Basketball Shoes
Random Entities:
- all NBA players
- all footwear brands
- unrelated sports disciplines
- random public figures
Why it doesn't work: Entities are random, topically unrelated, and dilute the main page topic.
Central Entity = Frequency × Relationship Strength × Content Position
Entities appearing frequently, strongly connected to others, and placed in key locations are considered central
Summary
Patent US9009192B1 demonstrates Google's advanced approach to understanding content through entities and the relationships between them.
Effective SEO increasingly relies on creating content that:
- Clearly defines central entities
- Builds proper relationships between entities
- Provides comprehensive coverage of related entities
- Maintains topical consistency and context
The key is creating high-quality, well-structured content that naturally integrates relevant entities, rather than attempting to manipulate their relationships for SEO purposes.
- Conclusion from patent US9009192B1