
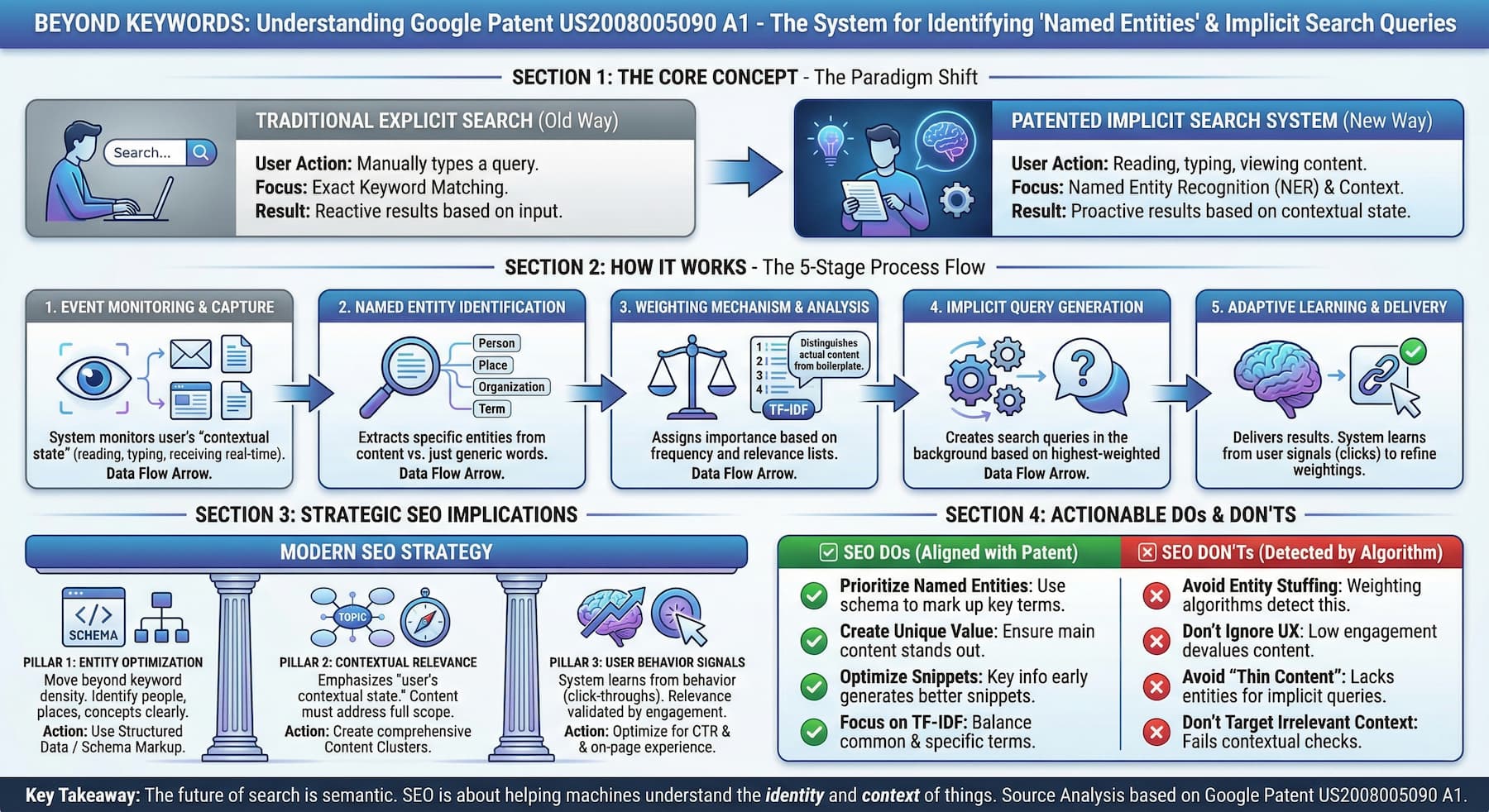
Google Patent US2008005090 A1 reveals how search systems identify named entities from a user's contextual state - documents being read, emails received, messages typed - and automatically create implicit search queries to deliver relevant information without requiring explicit searches.
What is the Patent About?
This patent (US2008005090 A1) is about systems and methods for identifying named entities and using them to create implicit search queries.
The invention addresses the problem that users often have access to relevant information on their devices but may not explicitly search for it. The system monitors a user's contextual state (such as what they're typing or reading) and automatically identifies named entities (like people's names, email addresses, or important terms) from these contexts.
Key aspects of the patent include:
- Identifying events associated with articles (documents, emails, web pages, etc.)
- Identifying named entities within these events
- Determining weights for each named entity based on their frequency in a data store
- Creating implicit search queries based on these named entities, with higher focus on entities with higher weights
- Delivering relevant search results to the user without requiring explicit searches
The system can extract named entities from various sources including emails, instant messages, documents, and web pages. It then uses these entities to generate implicit queries that run in the background, presenting relevant information to the user based on their current context.
As stated in paragraph 0018: "Embodiments of the present invention provide systems and methods for identifying a named entity. In one embodiment, a computer program, such as a query system, identifies an event associated with an article, identifies a named entity within the event, and creates an implicit search query comprising the named entity."
Key Patent Elements
The key elements of this patent (US2008005090 A1) include:
1. Named Entity Identification System
Identifies named entities (people, places, terms of interest) within various content sources.
As stated in paragraph 0043: "A named entity is a term, phrase, or other identifier that has been noted as being relevant to the user."
2. Event Monitoring
Captures and processes user activities (typing, reading, receiving messages).
Paragraph 0060 explains: "Events comprise historical, contextual, and real-time events. Contextual events are time sensitive."
3. Named Entity List Creation and Management
Creates and maintains lists of named entities from various sources.
Paragraph 0043: "In one embodiment of the present invention, the indexer 130 creates a named entity list, which can subsequently be used to identify named entities."
Weighting Mechanism
Assigns weights to named entities based on frequency and relevance. Paragraph 0051: "In one embodiment, the list of named entities includes a weight attribute associated with the named entity term."
Implicit Query Generation
Creates search queries automatically based on weighted named entities. Paragraph 0057: "The query system 132 receives an event, identifies a named entity in the event, creates an implicit query..."
Result Set Processing
Retrieves, ranks, and displays results without requiring user action. Paragraph 0073: "Once the query system 132 has received the result set and ranked the results..."
Adaptive Learning
Improves performance based on user interaction with results. Paragraph 0058: "The query system 132 keeps track of how often the user selects or otherwise expresses interest in articles..."
Memory Management
Optimizes storage of named entities between RAM and disk. Paragraph 0056: "In one such embodiment, the number of named entities stored in RAM may vary over time."
These elements work together to create a system that automatically identifies relevant information based on the user's context without requiring explicit search queries.
SEO Implications
While this patent is not directly about SEO, it offers valuable insights into how search technologies might work, which has several implications for SEO professionals:
Entity Recognition Importance
The patent emphasizes the value of named entities in determining relevance, suggesting that SEO should focus on properly identifying and emphasizing important entities within content. As paragraph 0052 notes: "Identified terms may improve the performance of implicit searches because they allow the query system to focus on terms of potentially greater interest to the user."
Contextual Relevance
The system evaluates content based on context, implying that SEO should consider how content relates to user context and intent. Paragraph 0097 states: "The query system merges them into a single list giving weight to the relevance score based on which list they come from."
User Behavior Signals
The patent describes using click-through data to refine relevance, suggesting that user engagement metrics likely influence search rankings. Paragraph 0063 explains: "The query system 132 may rely on click-throughs within the content display window to determine results in which the user exhibits particular interest."
Frequency and Weighting
The patent uses both term frequency (TF) and inverse document frequency (IDF) as ranking signals. Paragraph 0067 notes: "In another embodiment, the query system 132 extracts the inverse document frequency ('IDF'), which is defined as the inverse of how often a term appears in documents in general."
Content Differentiation
The system distinguishes between boilerplate and actual content, suggesting that SEO should focus on unique, valuable content. Paragraph 0132 explains how the system "is able to differentiate between boilerplate present in the article and content; the content is what is used for generating the implicit query."
Snippet Generation
The patent describes methods for generating snippets, highlighting the importance of how content appears in search results. Paragraph 0089 discusses how the system "generates snippets to be displayed with or in place of a link and title."
User Profiles and Personalization
The system leverages user profiles to personalize results, suggesting that SEO strategies should consider different user segments. Paragraph 0125 explains: "In one embodiment of the present invention, a user profile provides attributes, which may be used by the query system 132 to modify search queries, and/or result sets to provide the user with a personalized experience."
Cross-Document Relevance
The patent evaluates content across multiple documents and sources, suggesting that SEO should consider how content relates to other content both within and outside a website.
Strategic SEO Recommendations Based on US2008005090 A1
💡 What to Do:
Prioritize Entity Optimization
- Clearly identify and mark up important named entities in your content
- Use structured data/schema markup to help search engines identify entities
- As paragraph 0043 suggests, named entities are "term, phrase, or other identifier that has been noted as being relevant"
Create Entity-Rich Content
- Include relevant people, places, organizations, and concepts in your content
- Build content around entities that users in your industry frequently search for
- Paragraph 0045 mentions that "named entities may also comprise common terms or phrases of interest to the user"
Focus on Contextual Relevance
- Ensure content addresses the full context of a topic, not just keywords
- Create content that answers related questions users might have
- Paragraph 0062 notes the importance of "information relevant to the user's contextual state"
Optimize for User Engagement
- Create content that encourages clicks, longer time-on-page, and return visits
- Design for positive user experience signals
- Paragraph 0063 emphasizes how the system "learns from a user's behavior whether or not certain data streams or keywords are particularly relevant"
Develop Comprehensive Content
- Create content with appropriate depth and breadth on your topic
- Include related terms and concepts (TF-IDF optimization)
- Paragraph 0067 discusses how both term frequency and inverse document frequency are used to identify important content
Focus on Unique, Valuable Content
- Ensure your main content stands out from navigational elements and boilerplate
- Paragraph 0133 explains how the system identifies valuable content separate from boilerplate
Optimize Content Snippets
- Create compelling meta descriptions and ensure key information appears early in content
- Paragraph 0089 discusses snippet generation importance
💡 What to Avoid:
Avoid Entity Stuffing
- Don't artificially inflate entity mentions just for SEO
- The patent's weighting system (paragraph 0051) suggests algorithms can detect and devalue such manipulation
Don't Ignore User Signals
- Avoid focusing solely on keywords while ignoring engagement metrics
- Paragraph 0063 shows how systems may downweight content that users don't engage with
Avoid Thin Content
- Don't create pages with minimal unique content surrounded by boilerplate
- The system can differentiate between boilerplate and actual content (paragraph 0132)
Don't Overuse Generic Terms
- Avoid focusing on common words with high document frequency
- Paragraph 0068: "The word 'the' is likely to have a very high TF and a very low IDF since 'the' occurs frequently in many documents"
Avoid Irrelevant Keyword Targeting
- Don't target terms unrelated to your content's context
- The patent emphasizes contextual relevance throughout (paragraph 0097-0098)
Don't Create Disconnected Content
- Avoid content that doesn't relate to your site's overall topic or user interests
- Paragraph 0125 shows how user profiles and content relevance are connected
Avoid Misleading Titles and Descriptions
- Don't create clickbait that doesn't deliver on its promise
- The patent describes how systems learn from user engagement (paragraph 0063-0064)
Practical Implementation Examples Based on Patent US2008005090 A1
1. Entity-Optimized Product Page
Implementation: Create product pages that clearly identify and emphasize named entities relevant to your product.
Example: For a hiking boot product page: Mark up the brand name, model name, and designer using schema.org. Include related entities like "Appalachian Trail," "Gore-Tex technology," and "vibram soles." Create content sections addressing how the product relates to these entities.
Why it works: The patent emphasizes the importance of named entities (paragraph 0043-0046). By structuring content around important entities, you help search engines understand relevance and context.
2. Entity-Based Content Clusters
Implementation: Organize content into clusters around central entities relevant to your business.
Example: A financial services website might create content clusters around: "Retirement planning" (main entity), "401(k) accounts" (related entity), "IRA contributions" (related entity), "Social Security benefits" (related entity).
Why it works: Paragraph 0080 describes how the system combines keywords from multiple queries. Similarly, creating content clusters helps search engines understand relationships between topics.
3. User Behavior Optimization
Implementation: Analyze and optimize for user interaction signals that indicate content relevance.
Example: Identify pages with high bounce rates and analyze what named entities are missing. A/B test different content organizations to see which generates more engagement. Track which content sections users spend most time reading and expand those topics.
Why it works: Paragraph 0063 explains how the system "learns from a user's behavior whether or not certain data streams or keywords are particularly relevant." Search engines likely use similar signals.
4. Context-Aware FAQ Creation
Implementation: Create FAQs that address the full context around your primary topics.
Example: For a mortgage lender website: Identify common questions about mortgage rates. Create FAQ sections that address related entities (loan terms, credit scores, lenders). Structure content to answer questions at different stages of the customer journey.
Why it works: The patent describes analyzing "the user's contextual state" (paragraph 0027). By addressing the full context of user queries, you mirror how the system generates comprehensive results.
5. TF-IDF Optimized Blog Content
Implementation: Use TF-IDF analysis to ensure content includes appropriate keyword frequency and rare, valuable terms.
Example: For a blog post about digital photography: Include expected terms like "aperture" and "shutter speed" at natural frequencies. Add distinctive terms like specific camera model numbers or technical processes. Balance common terms with specialized terminology.
Why it works: Paragraph 0067 explains how the system extracts keywords based on term frequency and inverse document frequency. This approach mirrors that process.
6. Boilerplate Reduction Strategy
Implementation: Minimize repetitive elements and emphasize unique content on each page.
Example: Move lengthy navigation menus into collapsible elements. Reduce header/footer size to prioritize main content. Ensure each page has substantial unique content before template elements.
Why it works: Paragraph 0132-0133 describes how the system differentiates between boilerplate and actual content. Search engines likely make similar distinctions.
7. Click-Through Rate Optimization
Implementation: Create titles and meta descriptions that accurately represent content and encourage clicks.
Example: Instead of: "Best Running Shoes - Our Products" Use: "10 Best Marathon Running Shoes for Flat Feet (Tested by Pros)"
Why it works: Paragraph 0114 describes how the system tracks "when the user clicks on a link" to determine interest. Search engines use click-through rates as relevance signals.
8. Named Entity Content Audit
Implementation: Audit existing content to identify and enhance named entity coverage.
Example: List all product pages and identify key entities missing from each. Compare entity coverage against competitor pages. Enhance content to include missing entities and provide more context around existing ones.
Why it works: The patent's core focus is identifying named entities (paragraph 0042-0056). By systematically auditing and enhancing entity coverage, you align your content with how search engines may identify and evaluate relevant content.
9. User Intent-Based Navigation Structure
Implementation: Restructure site navigation based on user intent patterns and entity relationships.
Example: For a travel website: Group content by traveler intent ("Planning," "Booking," "Experiencing"). Create entity-based navigation paths (by destination, activity type, or travel style). Use breadcrumbs that reinforce entity relationships.
Why it works: Paragraph 0059-0060 describes how the system understands user context. By structuring navigation around user intent and entity relationships, you help search engines understand content relevance to specific user needs.
10. Snippet Optimization Strategy
Implementation: Structure content to create optimal snippets that encourage clicks from search results.
Example: Place key information in the first 100 words of each page. Create concise, information-rich paragraphs that work well as standalone snippets. Include key entities early in content where they can be captured in snippets.
Why it works: Paragraph 0089 explains how the system "generates snippets to be displayed with or in place of a link and title." Optimizing for attractive snippets improves click-through rates.
11. Entity-Based Internal Linking
Implementation: Create an internal linking strategy based on entity relationships rather than just keyword matching.
Example: Link between pages discussing the same named entities. Create hub pages for major entities in your industry. Use descriptive anchor text that includes relevant named entities.
Why it works: The patent discusses how entities are related across content (paragraph 0046-0048). By linking based on entity relationships, you reinforce these connections for search engines.
12. Contextual Relevance Enhancement
Implementation: Expand content to address the full context around primary topics.
Example: For a page about "home solar installation": Include sections on related entities (solar panels, inverters, battery systems). Address contextual questions (permits, tax incentives, maintenance). Create content that answers questions at different stages of consideration.
Why it works: Paragraph 0062-0063 explains how the system extracts context from various sources. By addressing the complete context, you provide signals of comprehensive relevance.
13. User Profile-Based Content Personalization
Implementation: Create content variants that appeal to different user segments based on their likely profiles.
Example: For a fitness equipment website: Create beginner-focused content for new visitors. Develop advanced content for returning visitors. Tailor product recommendations based on previous interactions.
Why it works: Paragraph 0125-0129 describes how user profiles affect search relevance. While you can't access individual user profiles, you can create content that appeals to different user segments.
14. Frequency-Based Keyword Prioritization
Implementation: Prioritize keywords in content based on their frequency in your industry and their specificity.
Example: Identify high-IDF terms in your industry (specialized terminology). Use these terms prominently in titles and headings. Balance with more common terms throughout body content.
Why it works: Paragraph 0067-0068 explains how term frequency and inverse document frequency affect keyword extraction. Using this same principle helps optimize content for relevant terms.
15. Click-Through Optimization for Internal Search
Implementation: Optimize internal search results based on user click patterns.
Example: Track which internal search results users click on most frequently. Boost those results for similar queries. Use this data to identify content gaps where users search but find no satisfactory results.
Why it works: Paragraph 0105-0106 describes how the system "keeps track of how often the user clicks on articles." Internal search optimization mirrors this learning process.
In Conclusion
Named Entity Recognition represents a fundamental shift in how search engines understand and evaluate content. As evidenced by patent US2008005090 A1, search technologies are increasingly focused on identifying, weighting, and contextualizing named entities rather than simply matching keywords.
For SEO professionals, this means optimizing content should center on properly identifying and emphasizing relevant entities, creating comprehensive contextual relationships between them, and ensuring content delivers genuine value that generates positive user engagement signals.
By implementing entity-focused strategies-from schema markup implementation to entity-based content clustering - websites can align with how modern search algorithms evaluate relevance and authority.
The future of SEO lies not just in what keywords appear on a page, but in how effectively content identifies and contextualizes the entities that matter most to users, creating rich semantic networks that search engines increasingly recognize and reward.
Summary
Patent US2008005090 A1 introduces a method for identifying named entities from user's contextual state and creating implicit search queries, making entity recognition, weighting, and contextual relevance fundamental components of how search systems deliver information - without requiring explicit user searches.
The core innovation lies in the entity weighting mechanism: named entities are assigned weights based on term frequency and inverse document frequency, with higher-weighted entities prioritized in implicit query generation. This creates a direct channel through which entity importance and contextual relevance influence search behavior.
For SEO strategists, the implication is clear: success depends on building content rich in relevant named entities - combining proper entity markup, contextual depth, user engagement optimization, and TF-IDF-aware content development. The keyword game and the entity game are now the same game.